Week #2 Report #
TODO #
Todo list of required parts to ensure that nothing missed
- Provide architecture
- Component Breakdown: Identify the major components and modules that will form your software solution. Outline their responsibilities and interactions to ensure a cohesive structure.
- Data Management: Determine how data will be stored, accessed, and manipulated within your application. Select appropriate databases or data storage solutions based on the project’s requirements.
- User Interface (UI) Design: Consider the user experience (UX) and design principles when planning your UI. Sketch wireframes or create mockups to visualize the layout and flow of your application.
- Integration and APIs: Assess any external systems, services, or APIs that need to be integrated into your application. Plan how these integrations will be implemented and how data will flow between systems.
- Scalability and Performance: Anticipate future growth and consider scalability aspects when designing the architecture. Ensure that your application can handle increasing user loads and data volumes without compromising performance.
- Security and Privacy: Incorporate appropriate security measures into your architecture to protect user data and safeguard against potential vulnerabilities. Consider authentication, authorization, encryption, and other relevant security practices.
- Error Handling and Resilience: Plan for handling errors and exceptions to maintain a reliable and resilient application. Define strategies for error logging, monitoring, and graceful error recovery.
- Deployment and DevOps: Consider the deployment process and DevOps practices that align with your chosen tech stack. Automate deployment tasks, implement version control, and establish a robust development workflow.
- Choose tech stack
- Evaluate the requirements and objectives of the project
- Consider important factors (e.g. performance, security, scalability, expertise of team members)
- Determine most suitable technologies
- Questionnaire
- Tech Stack Resources: Are you utilizing any project-based books that specifically cover your tech stack and help you build your project? If yes, please provide the names of these books (name at least 3). How do you anticipate utilizing these materials to enhance your knowledge and expertise in your tech stack?
- Mentorship Support: Do you currently have a mentor actively involved in your project? If yes, kindly share the name of your mentor and explain how their guidance has positively influenced your project. If you don’t have a mentor yet, have you considered seeking one? How do you believe having a mentor could contribute to the success of your project? Remember, having an experienced mentor that can guide you and your team is your responsibility.
- Exploring Alternative Resources: In addition to project-based books, what other resources have you explored to expand your understanding of your tech stack? This could include online courses, video tutorials, documentation, or any other sources that have been valuable in filling knowledge gaps. Please, name at least 3 resources
- Identifying Knowledge Gaps: Are there any specific areas within your tech stack where you or your team feel there are knowledge gaps or expertise is lacking? If so, how do you plan to address these gaps and ensure a well-rounded understanding of your chosen technologies? Please name the tech stack division in your team and outline how are you planning to deal with knowledge gaps
- Engaging with the Tech Community: Have you actively engaged with the broader tech community to seek guidance or learn from experienced professionals in your tech stack? This could involve participating in online forums and groups (telegram, discord or any other platform), attending local meetups (Kazan, Innopolis)? Do you have means to engage experts into critical tech stack problems through professional networks?
- Learning Objectives: What specific learning objectives have you set for yourself and your team in relation to your tech stack this week? How do you plan to achieve these objectives, and what strategies or resources will you employ to deepen your understanding?
- Sharing Knowledge with Peers: How have you been sharing your knowledge and expertise with your teammates? Have you organized any knowledge-sharing sessions or discussions to facilitate the exchange of insights and experiences related to your tech stack?
- Laveraging AI:How have you leveraged AI to compensate for any lacking expertise in your tech stack? Have you utilized AI-powered tools or platforms to expedite the process of acquiring knowledge and expertise in your tech stack?
- Tech Stack and Team Allocation
- How did you ensure that each team member was effectively assigned to appropriate tasks and responsibilities within the project?
- Provide detailed explanation of how team member responsibilities
Architecture #
Component Breakdown #
The diagram below depicts the architecture of our application:
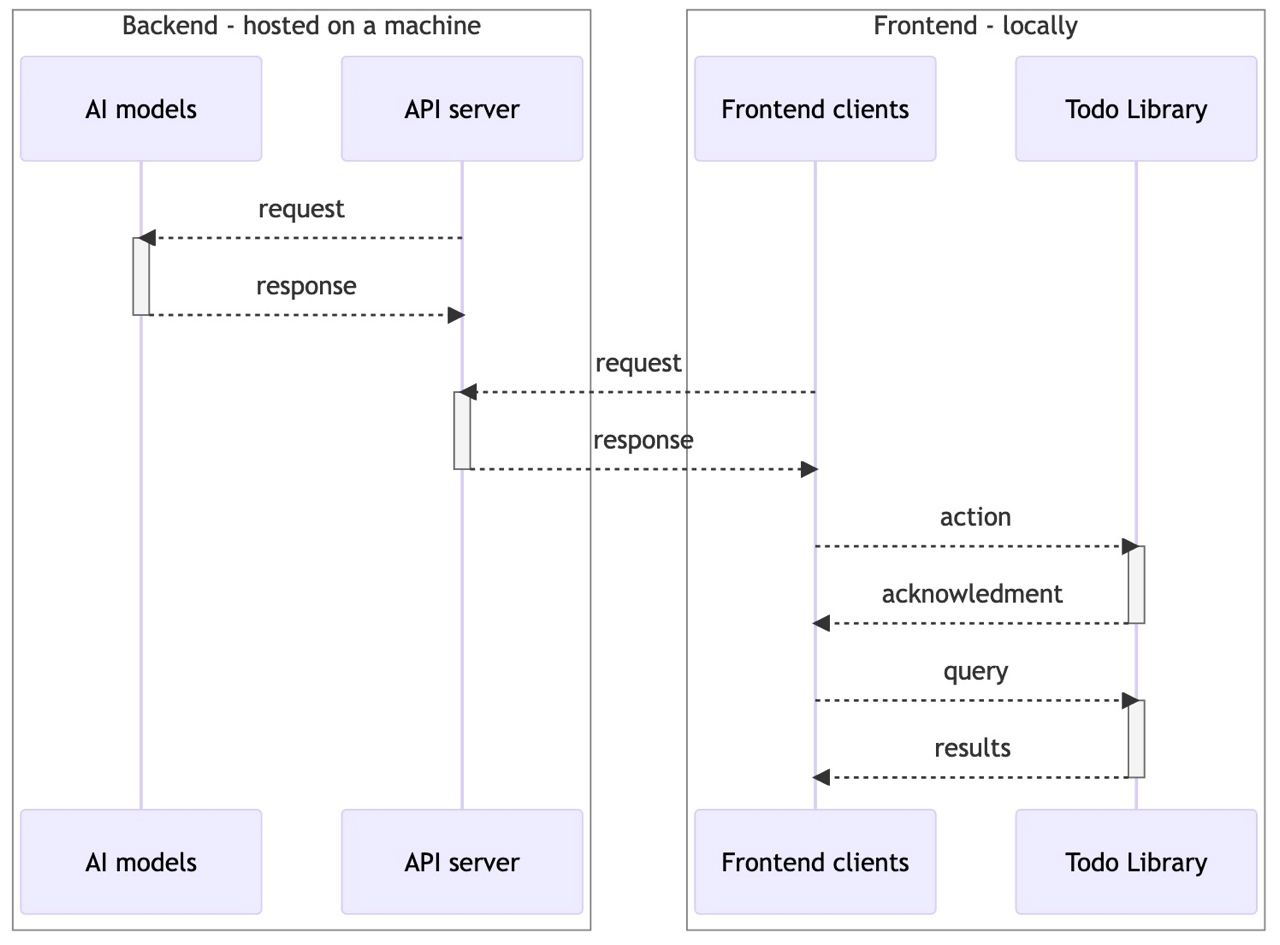
There are 4 main components that are divided into 2 groups: local and server-side.
Local:
- Todo Library contains main business logic of our app. It is responsible for parsing collections of todo entries and performing actions with them. Actions include queering, modifying, merging, performing any user-defined functions (i.e plugins written in rust for any automated data manipulation).
- Frontend clients are responsible only for representation of the data, OS-specific actions and communication with the server everything else is delegated to Todo Library.
Server-side:
- API server is used to handle communication of the client-side application with everything else. The main purpose of it is to be in the middle between Frontend and AI models, but in future it may be extended for more complex actions (e.g. communication with remote database)
- AI models are a set of different algorithms that would perform advanced automation actions like searching by meaning, automatic merge-conflict resolution and so on.
Data Management #
We are developing open source app, so we strongly respect user privacy. Main functionality is available without network access, since all data is stored locally on user device. For this purpose we are going to use NoSQL solutions Isar or Hive as supplement to the plain text files. Server part only perform ML actions, so we store credentials and user specific data in MongoDB. Temporal storage is done in memory.
Data Storage #
One of the main goals of our project is to be as future proof and open as possible, thus all data related to tasks will be stored in plain text files. Initially we will be using Org Mode format for that but with the possibility of adding new modules to support other file types or even databases.
And the main issue with plain text storage is not the size of files and thus speed of their processing (as our calculations suggest even having 10,000 tasks in a single file which is a really huge number, we would occupy only a few MB) but file edits by external sources while the app is running and conflicting versions of the same file.
Usually this kind of problems are handled by DBMS, however, we don’t want to use them for the reasons described earlier. To solve this issue we are planning to implement a smart merging tool for tasks. It would not only be useful inside our project, but also provide a handy way to resolve synchronization conflicts while using multiple devices + some way to synchronize them (e.g. cloud storage like DropBox or peer to peer solutions like Syncthing).
Task Data Model #
Task is the smallest core unit in our application. As an inspiration and
guidelines we used
Org Mode’s TODO item.
It contains the following fields(note that here field_name: Type notation is
used):
title: Linea single line describing a task, usually it’s enough to use only it without a body.body: Stringa multi line string that may contain anything, including tables, code blocks and so on.children: Collection[Task]a group of tasks each of which is a child of the current note in the tree hierarchy.priority: Option[Unsigned Integer]a priority indicator. The lower the number, the higher the priority (0 - highest priority). It is usually displayed as A, B or C in most todo apps.keyword: Worda property that indicates state of the task. Usually it has only 2 states: TODO and DONE. But in GTD there are other states such as SOMEDAY and INBOX.tags: Collection[Word]a collection of tags, that are usually used to simplify searching for the information.scheduled: Option[PeriodicDateTime]a periodic date time that represents when you are going to do this task.deadline: Option[PeriodicDateTime]a periodic date time that represents when the deadline for the task.properties: Collection[String]a list of other properties, that may be used to extend task management system.
Note that the following types are used as supporting ones:
PeriodicDateTimeis a type for scheduling events. It is a point in time that can be repeated. Refer to the Deadlines and Scheduling and Repeated tasks.Option[T]is a container that may contain some value of typeTorNone. It is used to signify presence/absence of something.Collection[T]is a container containing a group of elements.Wordis aStringwithout white space characters in it.Lineis aStringwithout linebreaks in it.
Notebook Data Model #
Notebook is simply a collection of tasks and is represented by a single file
tasks: Collection[Task]are all the top-level tasks in a file.keywords: Collection[Keywords]are per file keywords.
UI Design #
You can view our workflow and design mockups.
Here are main points and decisions of our design:
- Seamless and Non-disruptive UI: Design a distraction-free interface for adding tasks without interrupting workflow.
- Simplified and Efficient Sorting Process: Optimize task sorting with drag-and-drop options.
- Consistent Cross-Platform Experience: Ensure a consistent UX across desktop and mobile platforms.
- Offline Functionality and Reliability: Allow offline task management with automatic syncing.
- Mobile Inbox Processing: Design a mobile-friendly interface for efficient task processing on mobile devices.
- Performance and Speed: Optimize app performance for smooth and responsive user experience.
- Integration-Friendly Design: Enable integration with various task management systems and offer import/export options.
Integration and APIs #
We currently don’t have any integrations with external services. Our architecture primarily revolves around internal components and modules that work together seamlessly to deliver the intended functionality. As our To-do app evolves, we remain open to exploring opportunities for integrating with external services when it aligns with our objectives and security considerations.
Scalability and Performance #
Scalability and performance are crucial factors to consider when designing the architecture of a software solution. Here are some techniques to achieve scalability and optimize performance, that we plan to use in our project:
- Horizontal Scaling First and most common approach is to scale horizontally by adding more instances to distribute the workload. In our project architecture, we plan to introduce this technique for a service, responsible for ML and master backend service (Python), which are the only 2 types of services, in our microservice-like architecture.
- Asynchronous programming By offloading time-consuming tasks to background processes or queues, we will improve the responsiveness of our system. Processing events asynchronosuly allows the main application on server to handle IO-bound requests quickly, comparing to thos in synchronous programming.
- Modularity and Microservices We further enhance scalability, development, and maintenance by dividing our project’s logic into modular components that are not dependent on each other: Rust todo library, AI’s related service, master backend server, frontend client. The microservices architecture enables independent development, deployment, reusability and scalability of specific components, ensuring fault isolation and better overall system performance.
Security and Privacy #
Security and privacy are top priorities for our team in developing our project. We have taken several measures to ensure the protection of user data:
- HTTPS-only connection Firstly, our Web client would allow connections only via HTTPS, which will ensure security of transferring data via Internet.
- No sensitive data storage We do not ask any sensitive information from our clients, such as name, date of birth, to minimize the risks associated with data leakage.
- Encryption of data Secondly, we will use encryption and hashing algorithms for saving user passwords, which should help avoid data leakage in case of hacking.
- Synchronization with server is optional Our application offers users the freedom to choose whether they want to synchronize their data with a remote cloud server. Cloud-dependent features like ML (Machine learning) and Account synchronization are available but not mandatory, base functionality goes offline and covers most of user needs.
- Attack-resistant SSH As for our servers, we will use ssh keys for connection, denying use of passwords, as it is vulnerable to attaks.
Error Handling and Resilience #
There are many techniques we are planning to use in our project to avoid errors and unexpected bugs. By incorporating these robust error handling and resilience techniques, we improve the reliability of our software, minimize downtime, and deliver a more seamless user experience. These practices contribute to the overall quality and stability of our application, ensuring it can handle unexpected situations and recover gracefully from failures.
- Graceful Error Handling: We design our application to handle errors gracefully by providing meaningful error messages to users. Clear and informative error messages enable users to understand what went wrong and take appropriate actions. We avoid exposing sensitive information in error messages to maintain security.
- Exception Handling: We use exception handling techniques to catch and handle runtime errors in a structured manner. By catching exceptions at appropriate levels in our application’s code, we can prevent unhandled exceptions from crashing the system and provide alternative paths or recovery options
- Immutability: Making majority of variables immutable (meaning that after the value is assigned it cannot be changed) provides another layer of security. Firstly, concurrency becomes very convenient as we don’t have to think about concurrent read/write operations which is the main problem when creating such apps. Secondly, it’s harder to make mistakes when knowing that somewhere along the way the data won’t be be changed (contrary, when using mutable variable and passing it around to some functions, programmer can’t be sure if the function produces only result or also changes the variable). For mobile application we split mutable (state) and immutable (data) layers, so user interface could only ask state manager to perfrom action that updates data. Afterwards, UI will get updates reactively. Yes, internally this approach involve side effects, but they are highly isolated from other system.
- Type-level errors: Rich type systems allow encoding error information
into the type signature, which is a lot more secure and clearer than throwing
errors and hoping that they will be handled appropriately. For example,
Option[T]described earlier is a lot better than using error codes (such as -1 in many C/C++ applications) or null values because some functions are always returning a value and some may return null. The same concept is used in mobile app because dart offer nullable types and they are explicitly differ from non-nullable,String?is notString. - Borrow checker: It is another concept which ensures security in terms of memory manipulations. If variable(or reference) is immutable, then there aren’t any restrictions on reading it, but if variable(or reference) is mutable, then only 1 piece of code(usually function) can use it and others can’t unit this piece of code has finished. Also if the variable is not used and won’t be used any more it is freed, which ensures that there are no memory leaks.
- App global error handler this part is specific for GUI clients, like mobile app. Because, user couldn’t be notified as easy as in terminal, we want to reduce uncaugh errors. But sometimes, exception raises from dependency in example and developer just could not predict user environment setup and depdendency behavior. So, to not ignore exception nor fall the app, we handle all such cases globally and navigate user to special screen similar to “oops, error … occured”.
- Separation of Logic into Services and Modules We adopt a modular approach by separating the application’s logic into different services that communicate with each other, instead of running the whole logic on single host. This architectural design ensures that if one part of the application fails, it does not result in a complete system failure. Moreover, we will use separate Rust library, that will handle tasks representation and modification. This library will run on both client & server, which helps incapsulate common logic in different places.
Network related errors #
Also, we recognize the importance of error handling and resilience especially in the context of our microservices architecture. With modules distributed across different hosts communicating with each other via APIs, we place special emphasis on addressing errors related to API interactions, such as serialization and validation. Here’s how we address these specific aspects:
- Serialization Errors: We ensure that data serialization between microservices is handled correctly to prevent errors during the conversion of data structures into a format suitable for transmission. We follow best practices and use well-established serialization techniques, such as JSON or Protocol Buffers, to ensure compatibility and minimize the chances of serialization-related errors.
- Validation Errors: We pay close attention to data validation within our APIs to maintain data integrity and prevent invalid or inconsistent data from entering the system. We implement robust validation mechanisms at both the API input and output levels, verifying that the received data adheres to expected formats, constraints, and business rules. By validating inputs and outputs, we can catch errors early and provide informative error messages to guide users and developers in resolving any issues.
- Error Responses and Status Codes: In our API design, we establish a consistent approach to error responses and status codes. We define clear conventions for communicating errors, including appropriate HTTP status codes, standardized error payloads, and error message formats. Consistency in error responses helps in understanding and handling errors effectively, both within our microservices ecosystem and for external consumers of our APIs.
By considering these aspects within our microservices-like architecture, we effectively address errors related to API interactions. We prioritize proper serialization and validation to maintain data integrity and compatibility. These practices contribute to the overall stability, reliability, and resilience of our microservices ecosystem.
Deployment and DevOps #
For the deployment and DevOps practices of our project, we will follow a set of strategies and use appropriate tools to ensure smooth and efficient deployment processes. Some key considerations and actions include:
- Continuous Integration (CI):
We will implement a continuous integration (CI) to automate the build, testing (unit-testing, integration tests, and others) , and deployment processes. This will allows us to catch bugs early, ensure code stability, and support confident deployments. Most probably we will use Github Actions.
For Python, we will use such tools:
isort,black,flake8,mypy. All of them help identifying bugs, code smells, and unexpected behaviours in our programs. - Continuous deployment (CD): Continious deployment is also important part of slim and up-to-date application, it will help us deliver updates on time, according to a given action pattern. Also will be implemented via Github Actions.
- Containerization (Docker): We will utilize containerization technology, especially Docker, to package our application and its dependencies into lightweight and portable containers. This approach enables consistent deployment across different environments and simplifies the management of dependencies.
By incorporating these deployment and DevOps practices, we aim to achieve efficient, reliable, and scalable deployments while maintaining a robust development workflow and ensuring the stability and performance of our application.
Tech Stack #
Requirements and Objectives of the Project #
As described earlier, our project is a task management tool consisting of several modules. Thus the main goal is to provide nice user experience while managing tasks in a manner similar to GTD.
Project objectives:
- Future-proof => open-format local data storage
- AI-powered to automate routine tasks
- Performance and responsiveness
- Open source
- Easily extensible with new modules
Chosen Technologies #
For app we chose:
- Flutter for UI applications, since it is crossplatform and declarative.
- Rust for Todo library, since it’s rich type system which is suitable for such data processing tasks and no runtime environment requirements, which leads to better cross-platform developing
- Python with FastAPI for Backend, since it’s very extensible and easy to maintain framework.
- Python for ML, since it has the biggest ML community thus a lot of models and libraries
Questionnaire #
Tech Stack Resources: Are you utilizing any project-based books that specifically cover your tech stack and help you build your project? If yes, please provide the names of these books (name at least 3). How do you anticipate utilizing these materials to enhance your knowledge and expertise in your tech stack?
Answer:
- Book The Rust Programming Language
- Clean Architecture by Robert C. Martin
- Beginning App Development with Flutter: Create Cross-Platform Mobile Apps 1st ed. Edition by Rap Payne
Mentorship Support: Do you currently have a mentor actively involved in your project? If yes, kindly share the name of your mentor and explain how their guidance has positively influenced your project. If you don’t have a mentor yet, have you considered seeking one? How do you believe having a mentor could contribute to the success of your project? Remember, having an experienced mentor that can guide you and your team is your responsibility.
Answer: Currently we don’t have a mentor who is actively involved into the project development because we consider ourselves quite experienced in building applications. However, most members of our team took course aimed to provide extensive knowledge and modern approaches for implementing task management system that originates from the GTD. The author, Alexandr Votyakov, actively communicates with all the members of the course, thus any our questions regarding task management can be addressed to him.
Exploring Alternative Resources: In addition to project-based books, what other resources have you explored to expand your understanding of your tech stack? This could include online courses, video tutorials, documentation, or any other sources that have been valuable in filling knowledge gaps. Please, name at least 3 resources
Answer:
- Boring flutter show
- FastAPI docs
- Flutter docs
- No Boilerplate is a great YouTube channel that has a lot of videos about rust, for example consider Rust tests are MAGIC
Identifying Knowledge Gaps: Are there any specific areas within your tech stack where you or your team feel there are knowledge gaps or expertise is lacking? If so, how do you plan to address these gaps and ensure a well-rounded understanding of your chosen technologies? Please name the tech stack division in your team and outline how are you planning to deal with knowledge gaps
Answer: Our team uses open resources to close gaps and continues developing skills to achieve good project quality. For instance resources covered in questions 1 and 3.
Tech Stack Division:
Person Responsibility Alexandr Ragulin Rust library Nikita Gurniak Flutter app Diana Tomilovskaya Flutter app Stepan Tsepa Python backend Vladislav Urzhumov AI module Engaging with the Tech Community: Have you actively engaged with the broader tech community to seek guidance or learn from experienced professionals in your tech stack? This could involve participating in online forums and groups (telegram, discord or any other platform), attending local meetups (Kazan, Innopolis)? Do you have means to engage experts into critical tech stack problems through professional networks?
Answer:
- Rust discord community
- One of our team members is a scala developer and participated in It’s Tinkoff scala meetup scala is a functional language, thus knowledge of it contributes to better Rust understanding
- ???
Learning Objectives: What specific learning objectives have you set for yourself and your team in relation to your tech stack this week? How do you plan to achieve these objectives, and what strategies or resources will you employ to deepen your understanding?
Answer: We want to grow as developers and learn new technical aspects of already known and new technologies. So, project based learning is perfect choice! Flutter, Rust, AI models and python backend development are our main areas of interest in terms of this project. As mentioned earlier we plan to learn technical skills by utilizing different resources.
Sharing Knowledge with Peers: How have you been sharing your knowledge and expertise with your teammates? Have you organized any knowledge-sharing sessions or discussions to facilitate the exchange of insights and experiences related to your tech stack?
Answer: We organize peer to peer and group meetings to share our knowledge and experience. In our workflow we also utilize merge requests to discuss any issues and share new ideas.
Leveraging AI:How have you leveraged AI to compensate for any lacking expertise in your tech stack? Have you utilized AI-powered tools or platforms to expedite the process of acquiring knowledge and expertise in your tech stack?
Answer: Developer(our) experience has been drastically improved since LLMs were released. For example, GitHub Copilot and you.com are the 2 most used AI technologies in our team. Also the user’s experience can be improved using AI. Artificial Intelligence algorithms tend to be useful in task classification and context understanding. Thus, JustOrgYou’s AI part is aimed to classify tasks and suggest the best task-directory distribution due to context. Also, AI algorithms may warn about similar or closely-related tasks to help user avoid duplication. Natural Language Processing plays a huge role in
Feedback
1. Component Breakdown
Good, I like how you utilised sequence diagram to reprint your component
2. Data Management
Impressive!!
3. UI Design
Design a distraction-free interface for adding tasks without interrupting workflow.
How ca you ensure that? I advice you to conduct usability testing to ensure what are you trying to achieve.
In the UI part you have to provide how will you do it. Not just what you are going to do it. Because without the how it’s just words, right?
Where and how to access designs?
4. Integration and APIs
But you integrate with your own API :)
5. Scalability and Performance Good
6. Security and Privacy Good
7. Error handling and Resillience You will do all of that? I highly doubt that it’s manageable. Maybe pick one or tow and focus to perfect them.
8. Deployment and DevOps Very Good
Answering questioner Answering for the questioner is good!
Overall The report is very good. I like your understanding of what to do. Looking forward to see your results.
Grade 5/5
Feedback by Moofiy