Week #3 #
Developing the First Prototype and Creating the Priority List #
Technical Infrastructure #
For the initial launch of the models, we used a laptops with NVIDIA RTX 3060 and NVIDIA GTX 1650M GPUs. When the prototypes were launched successfully, for the training we transitioned to using server with an NVIDIA TESLA P40 GPU. This powerful infrastructure allowed us to handle the computational demands of our deep learning tasks efficiently.
Backend Development #
- Blur Detection Model:
For the Blur Detection model, we adopted the D-DFFNet, which was trained on a specialized dataset. The model showed promising results during testing on our internal dataset, as detailed in our GitHub issue. This model leverages depth and depth-of-field cues to enhance blur detection accuracy significantly.



- Image Grouping Model:
For the Image Grouping model, we used CVNet, guided by the research in this paper. The model was trained on the Oxford5k and Paris6K datasets. We tested it firstly on Oxford5k dataset, then edited some code to add the ability to run our own photos through the model and exported model we tested on custom dataset.
Frontend Development #
Our application was developed using Kotlin Multiplatform Compose, leveraging the IntelliJ IDEA environment for an efficient development workflow. Kotlin Multiplatform allows us to share code across multiple platforms, ensuring a seamless and consistent user experience. We used Hi-Fi UI Prototype v2.0 from previous week.
Data Management #
For the Minimum Viable Product (MVP), we prioritized model development and application functionality over data management. As such, we did not initially implement a database. However, in the next phase, we plan to integrate a robust database solution using SQLite and the Room library. This will enhance our data storage and management capabilities, providing a solid foundation for future application scalability.
Prototype Testing #
The testing phase involved evaluating the models’ accuracy and desktop app testing. Currently, we are satisfied with model accuracy, but the inference time may need some improvement in the future. Moreover, we tried the desktop application, and are unsatisfied with screen space wastage, that we will make adjustments. Also, we created CI/CD pipelines based on Gradle and CMake building for different operating systems to improve testing In plans, CI/CD pipelines for deployment using GitHub Releases
Weekly Progress Report #
In the backend development phase, we successfully implemented two models: Blur Detection and Image Grouping. Here are the key accomplishments:
- Integration with Java using JNI:
- We utilized the Java Native Interface (JNI) to enable calling C++ code from Java, facilitating seamless integration between the models and the Java-based application.
- Model Execution with ONNX Runtime:
- Incorporated the ONNX Runtime library into our C++ code, allowing to run the models on multiple operating systems and devices, including Windows, Mac, Linux, Android, and iOS.
- Exported the trained models in the .onnx format for compatibility and deployment efficiency.
For Blur Detection Model #
- Image Upload with Magick++:
- Integrated the Magick++ library (a C++ API for ImageMagick) to support a wide range of image formats.
- Developed code to handle image uploading and preprocessing.
- Model Execution:
- Implemented the code to execute the blur detection model on the uploaded images.
- Connected the C++ backend logic with the Java application, ensuring smooth functionality.
Here you can see screenshots of blur-detection model work:


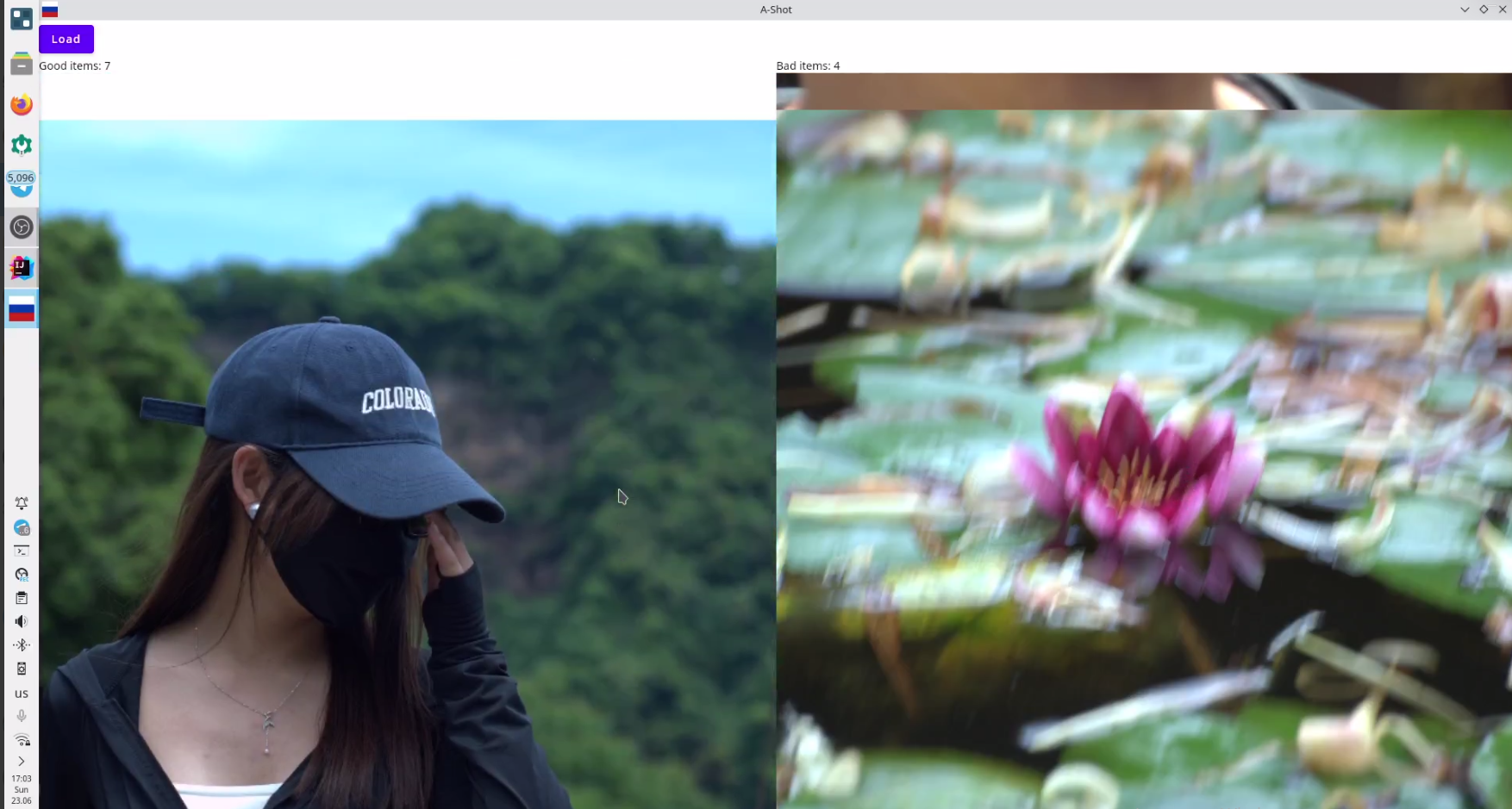
Here you can see the video of blur-detection model work
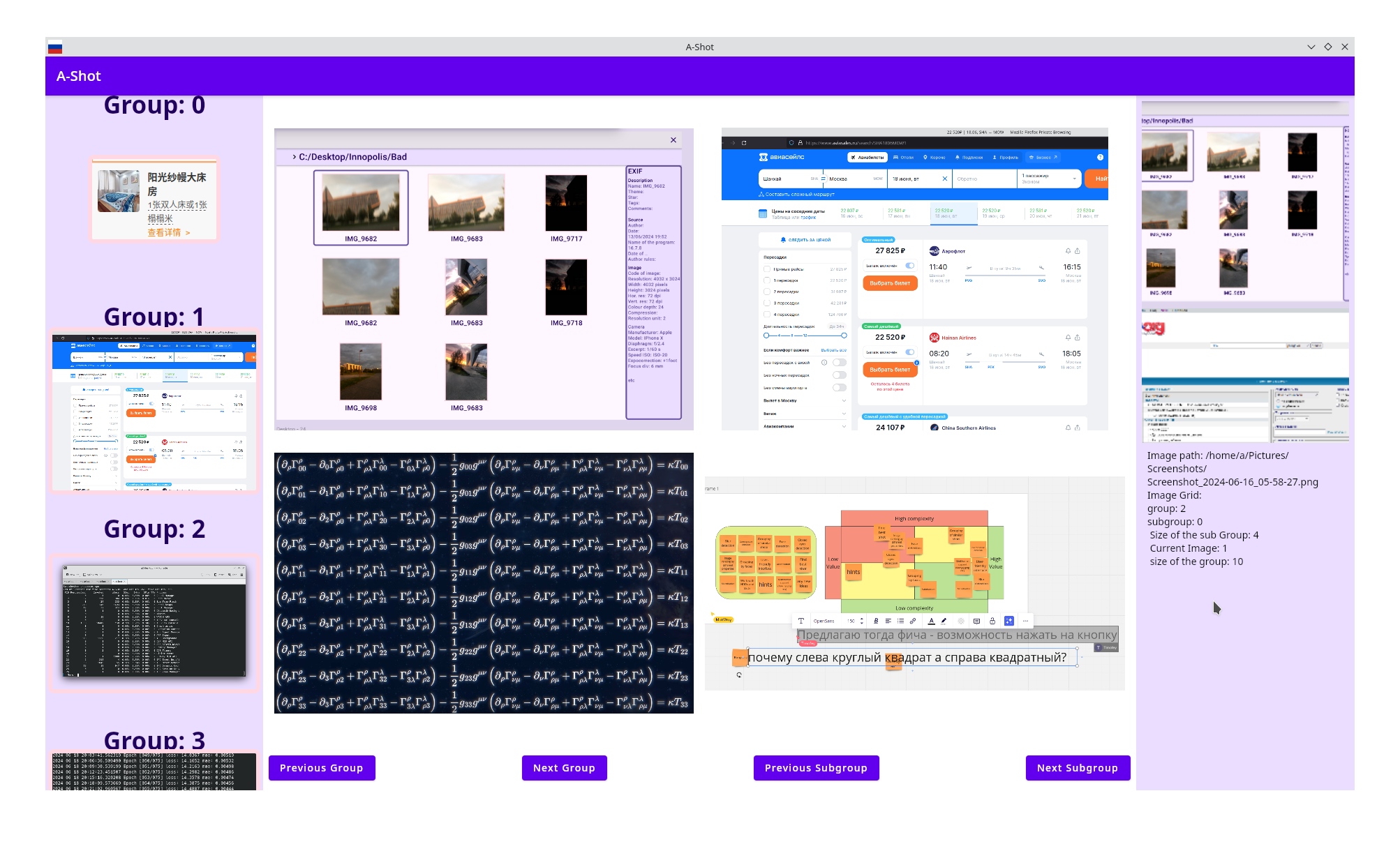
Here you can see screenshots of image grouping model work:



Frontend Development #
- Integrated most of the UI components into the existing UX skeleton created in the previous week.
Here you can see the screenshots of working prototype:
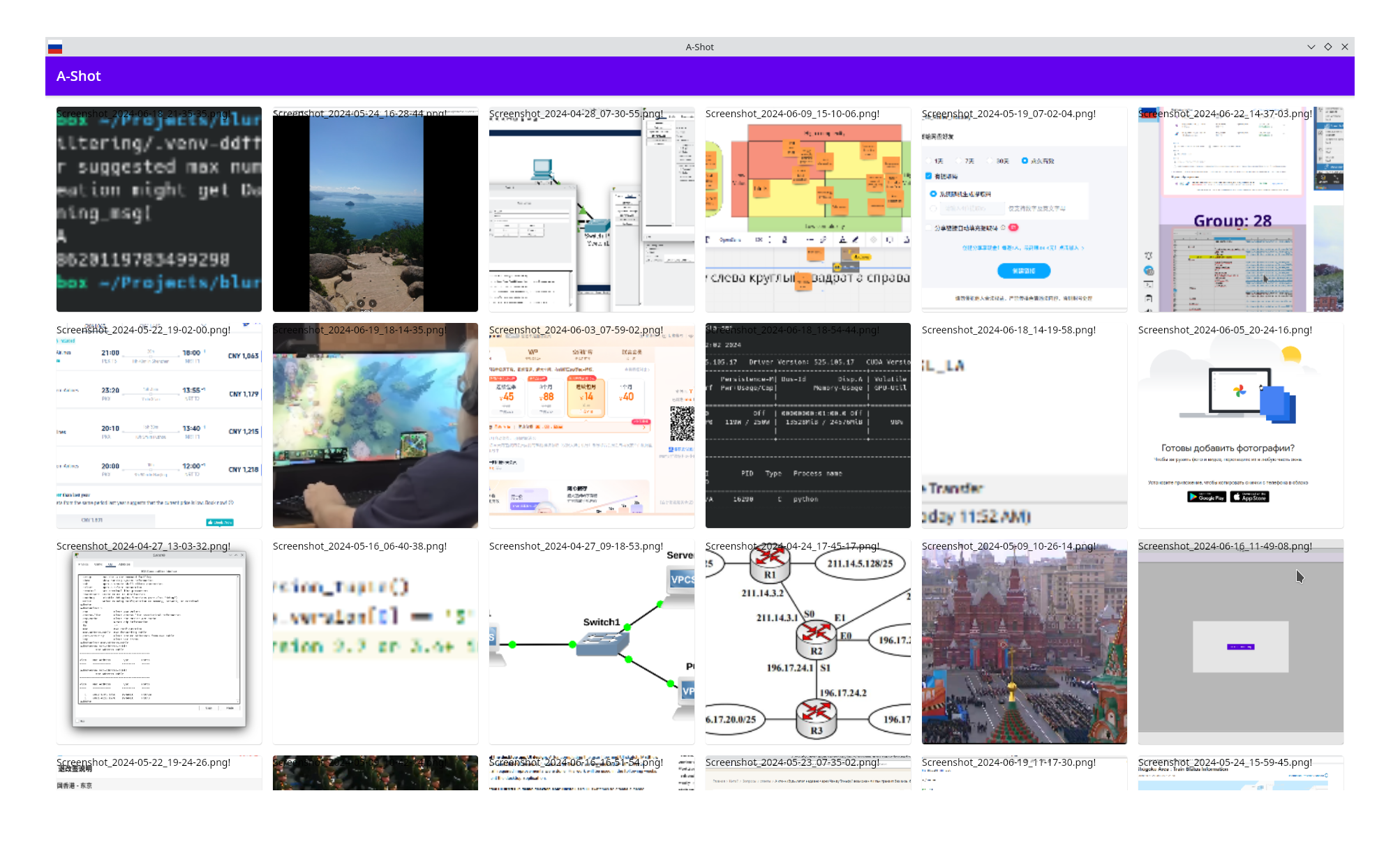
Here you can see the video of working prototype
Testing and CI/CD #
- Conducted thorough testing of the application and models to ensure reliability and performance.
- Implemented a CI/CD pipeline to automate building processes, enhancing development efficiency and consistency.
Challenges & Solutions #
Challenge 1: Running Trained Models from the Application
Problem: Directly calling code from Java and Python using libraries, or running a separate subprocess and using stdout/in for communication, was not suitable for our requirements.
Solution: We used onnxruntime, a tool that allows neural networks to run on any device. The models were exported to the .onnx format. We then wrote a C++ library that leverages ImageMagick for image uploading and onnxruntime for running neural models. The application accesses this library via JNI (Java Native Interface).Challenge 2: Dependencies for Running Our Library
Problem: Our library requires onnxruntime and ImageMagick to function.
Solution: We compiled these libraries from source with the necessary configurations and included them in our library.Challenge 3: Exporting the Model with Specific Functionality
Problem: The model required two photos to train and return a similarity score, but we needed a feature vector from a single photo input. Additionally, there was an export error that was difficult to track due to a lack of documentation.
Solution: We parsed and analyzed the model’s code and wrapped the model class in another class to ensure the necessary functions were called correctly.
Conclusions & Next Steps #
Despite significant progress, several tasks remain:
Models Performance Improvement:
- Enhance the current models’ performance through additional training and fine-tuning.
- Optimize the blur detection model to reduce complexity and weight.
- Integrate the image grouping model into our application.
Frontend Completion:
- Address UI issues identified during testing, such as excessive space usage, and brainstorm new ways to update UI features.
- Finalize the remaining parts of the front end to ensure complete functionality and a polished user experience.
Database Integration:
- Integrate SQLite and Room for database management to improve application performance and user experience. This integration will streamline data handling processes and eliminate the need for importing libraries every time.