Week #6 #
Presentation: #
Weekly Progress Report: #
Frontend Development: #
- Get rid of the loading screen blocking the interface: The screen has been successfully replaced, and the interface updates as the download progresses.
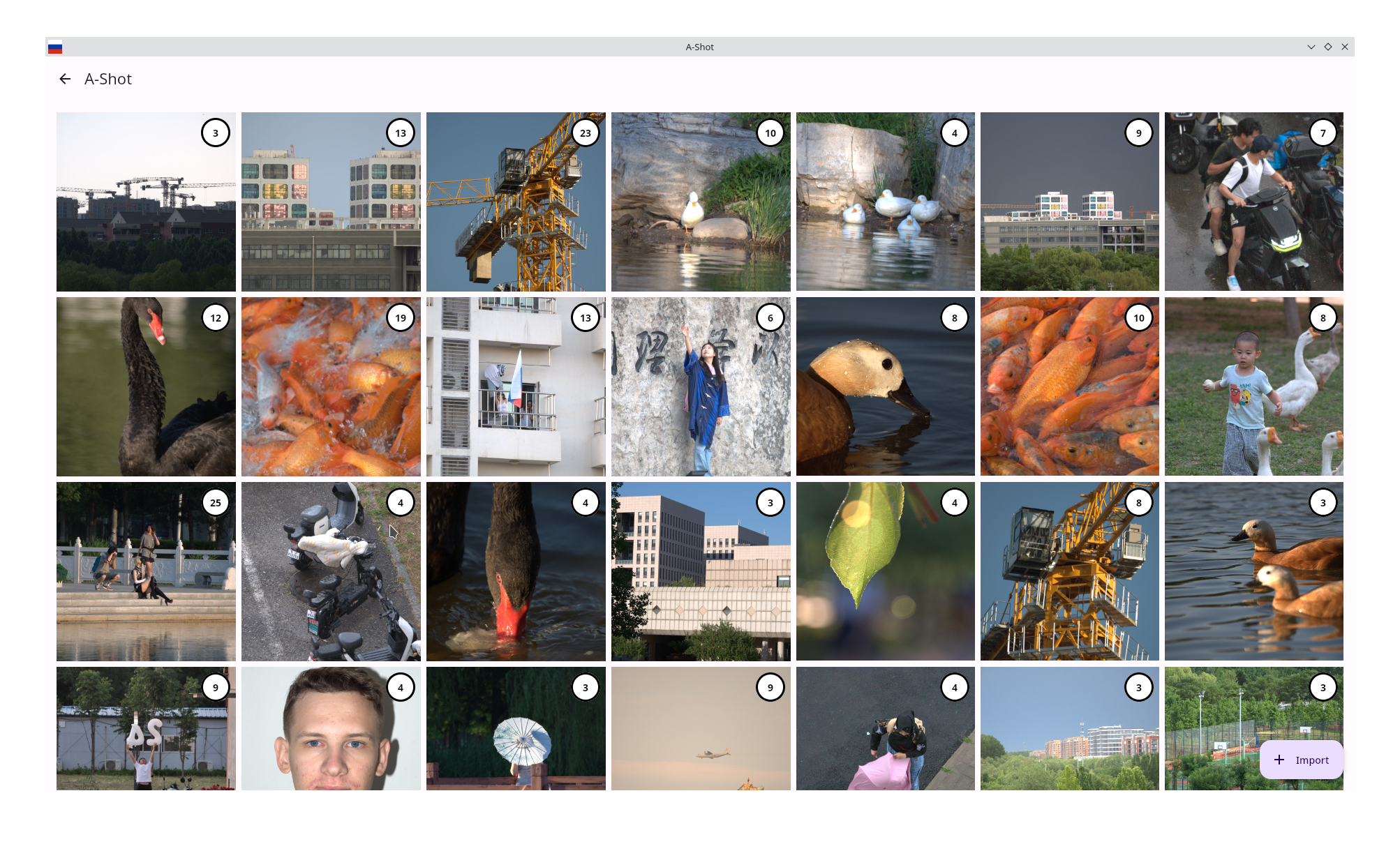
- Fix the thumbnail logic: Thumbnails are created using Magic++ as images are imported and saved to the database, which improves UI performance and eliminates freezes.
- Fix the screen with categories of imported images (the same screen with 2 buttons: Grouped and Tailpond).
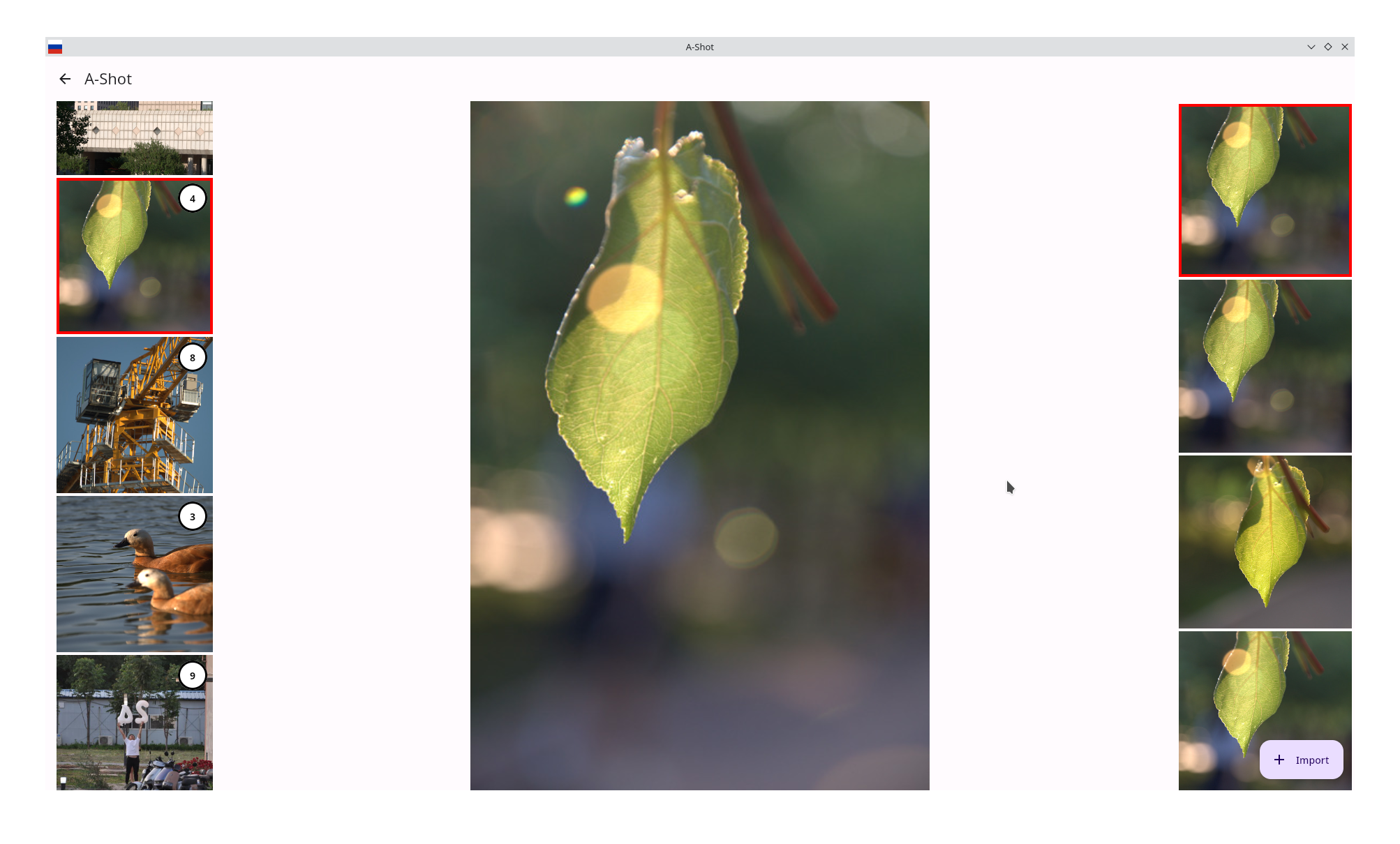
- Improved burst for images from the Side Sheet: fixes were targeted to correct the draw of the burst, and three images from the group can now be seen in the Side Sheet.
- Side Sheet improvements: our team moved the Side Sheet to the right and added the ability to hide it, allowing for more careful viewing of images
Overall, UI interface became more user-friendly, our team changed main color to the white
Machine Learning: #
- Connect the grouping model to our application: We have a model for grouping photos (see Week 3 report), which produces feature vectors that can be compared with each other, then groups the images according to these vectors. This allows users to search for similar frames in the application.
- Compare feature vectors to compare images (see Challenge 1).
- Optimize models to improve the performance of the import (see Challenge 2). Our team searched the ways how we can do our models faster
Challenges & Solutions #
Challenge 1: Add grouping model to the application
Problem: Our model takes a photo and produces a feature vector (1x2048). How can we compare them?
Solution: The model has been trained to produce vectors such that the cosine similarity between similar images tends to 1, and between different ones tends to -1. We use this metric as the distance between two vectors to determine if two pictures are similar. However, we need to form groups of images. To do this, we use clustering. K-means and K-nearest neighbors are not suitable because they require specifying the number of clusters in advance, which we do not know. Therefore, we chose DBSCAN. This algorithm forms clusters without specifying the number of clusters and works well in difficult cases where clusters cannot be separated by a straight line.Challenge 2: Optimize models
Problem: Long import times (~1 second per image = ~17 minutes per 1000 images).
Solution: We try optimize a large model with more than 100 million parameters by creating a student model to replicate the performance of the teacher model. The goal is to make the model faster and more efficient while maintaining accuracy. The student model will be trained to predict the outputs of the teacher model, ensuring similar performance with reduced computational requirements.
Conclusions & Next Steps #
This week was productive, and our team is now one step away from deploying our product. Several tasks remain:
- Frontend:
Some UI improvements still need to be finished:
- Slide bar
- Dark theme
- Color palette
- ML: Model optimization like solution in the challenge
- Multiplatform: Our goal is to create a single program file, which can be a positive solution for potential users. This will allow us to make our program multiplatform for Windows, and in the future, this development may be helpful for MacOS, Android, and iOS applications.
- Presentation: We should complete presentation, deploy and protect our product