Week #2 #
Tech Stack Selection #
According to the chosen project, the following tech stack was formed for ensuring smooth execution and long-term success. This week, we evaluated various technologies and tools, considering factors like scalability, performance, security, and our team’s expertise. Our final tech stack is as follows, divided into three layers:
Android: #
- Android: Android’s widespread adoption allows us to reach a broad audience with high accessibility to a large user base.
- Kotlin: A modern, concise, and safe programming language that integrates nicely with Android, reducing boilerplate code and increasing development efficiency.
- Jetpack Compose: A modern toolkit for building native UI. It simplifies and accelerates UI development on Android with less code, powerful tools, and Kotlin APIs.
- Retrofit: A type-safe HTTP client for Android and Java, making it easier to connect to a web service with a REST API, which is essential for sending the fridge image to our remote API.
- Room: An abstraction layer over SQLite, providing robust database access to SQLite. It’s great for storing recipes locally in a structured and accessible manner.
- CameraX: An addition to Jetpack that makes it easier to add camera capabilities to our app. Its purpose is to take photos of the fridge’s contents.
Backend: #
The backend of our application is designed to handle several critical functions:
- Data Persistence: Ensure the secure and efficient storage of user data, including personal information and favorite recipes.
- Authentication: Manage user authentication processes to ensure secure access to the application.
Tech stack: #
- Java: Chosen for its robust performance, scalability, and widespread use in enterprise applications.
- Spring: A comprehensive framework that simplifies the development of Java applications and offers built-in support for security, data access, and web services.
- Docker: Ensures consistent development environments, enables microservices architecture, and simplifies deployment.
- PostgreSQL: Serves as the primary database for our application, providing reliable and efficient data storage for user information and favorite recipes. Its advanced features and strong ACID compliance ensure the integrity and consistency of our data.
ML: #
- Python: The primary programming language for ML efforts.
- Google Colab: Chosen for its accessible and scalable environment for developing and training ML models. Moreover, Colab provides free access to powerful GPUs.
- YOLOv8: Pretrained model known for its high performance in object detection tasks. This model will serve as the base for ingredients recognition.
- Roboflow: Used for dataset management and creating annotations for images. Roboflow simplifies the process of creating and managing custom datasets, which is crucial for training object detection models on specific grocery products.
- CVAT: Utilized for creating detailed annotations for custom datasets.
- Kaggle: Used to source additional datasets that can enhance the training of the object detection model.
- Flask/FastAPI: These lightweight web frameworks will be used to deploy our ML models as APIs.
Architecture Design #
Component Breakdown: #
Frontend: Android App
- Technology: Kotlin and Jetpack Compose
- Features:
- Photo Tab: Capture or upload photos for AI food recognition.
- Main Feed Page: Search recipes by name, ingredients, or AI-generated suggestions.
- Profile Page: Manage personal information, settings, and favorite recipes.
Backend: Java with Spring (Containerized using Docker)
- Technology: Java, Spring, Docker
- Features:
- User Authentication: Secure user authentication and account management.
- Data Persistence: Store and manage user-specific information, favorite recipes, and profile data.
- Calorie Calculations: Calculate and recommend daily calorie intake based on user data.
- API Integration: Handle data exchange between the frontend and backend, ensuring smooth functionality and data flow.
ML Models: Python Scripts
- Technology: Python, YOLOv8, PyTorch, Roboflow
- Features:
- AI Food Recognition: Identify food items from uploaded photos.
- AI Recipe Generation: Generate personalized recipes based on recognized ingredients.
- Personalized Recommendations: Suggest recipes and daily menus based on user preferences and dietary restrictions.
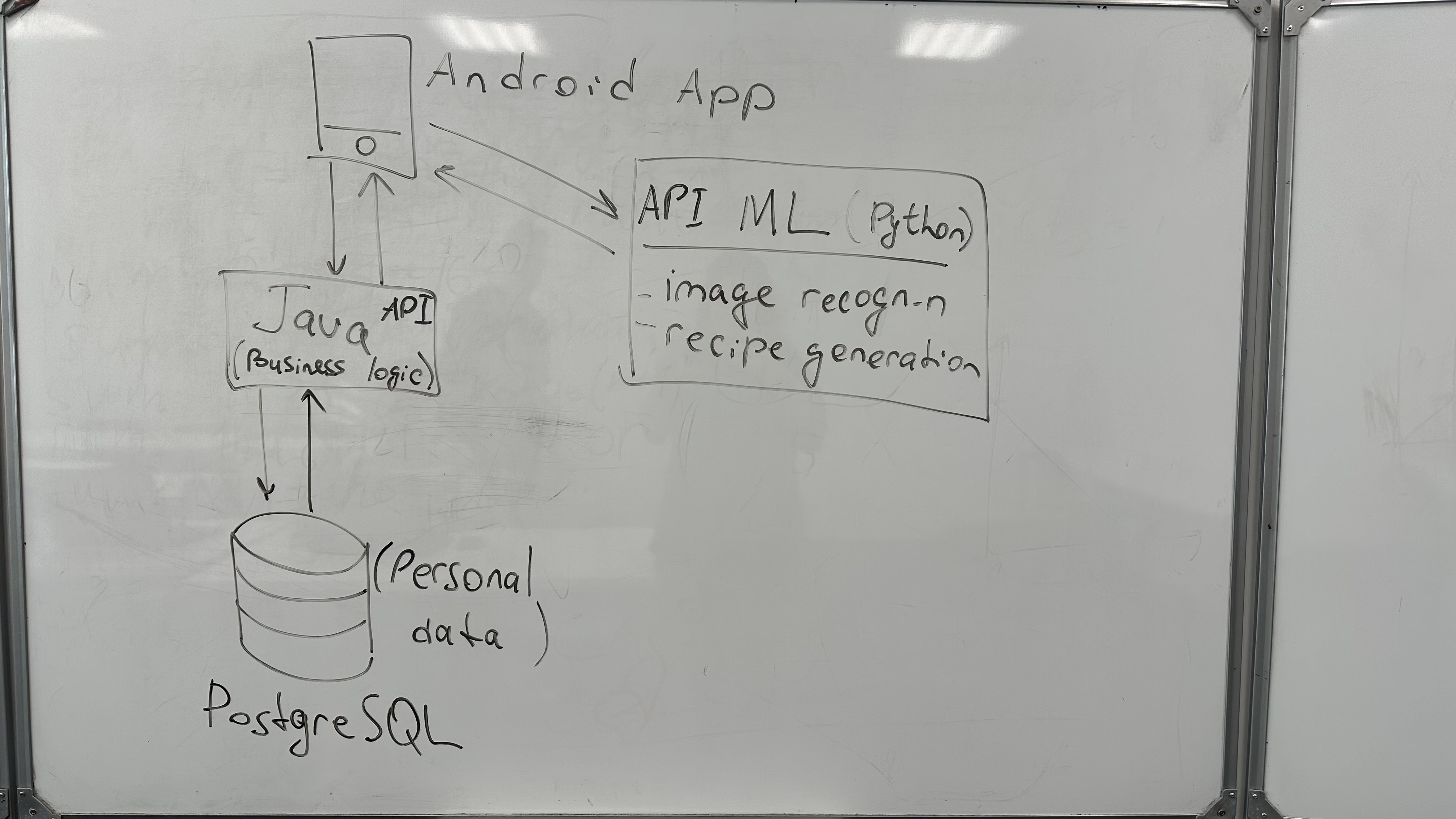
Data Management: #
- Database: PostgreSQL for reliable, robust, and scalable data storage. Room for local storage on the Android app.
- Database Tables Breakdown:
- User Table: Stores personal information of users.
- Columns:
- Id: Unique identifier for each user.
- Nickname: User’s chosen display name.
- Height: User’s height.
- Weight: User’s weight.
- Age: User’s age.
- Columns:
- Favorites Table: Stores user’s favorite recipes.
- Columns:
- UserId: Identifier linking the favorite recipe to a specific user.
- Name: Name of the favorite recipe.
- Recipe: Details or content of the recipe.
- Date_added: The date when the recipe was added to favorites.
- Columns:
- User Table: Stores personal information of users.
User Interface (UI) Design: #
- Homepage:
- Features recommended recipes and a search bar for recipe names.
- Camera Page:
- Includes a camera for capturing images of a user’s refrigerator.
- Allows users to search for recipes based on the ingredients identified in the image, even if some ingredients are not recognized.
- Profile Page:
- Stores favorite recipes and user profile information.
- Design Inspiration:
- The app’s design draws inspiration from the user interfaces of Yandex Delivery and YouTube.
Integration and APIs: #
For implementation, we used a Mistral API, specifically a client library written in Python. Mistral provides an API for requesting their models. They have 3 models for generating text, and we chose “Mixtral 8x22B” because it was the most suitable for us, providing a good tradeoff between its cost and performance. For the integration of the API, we plan to receive ingredients from the backend of the mobile app and pass them to our model’s request. Then the recipe will be generated in JSON format, and we will process it, save it, and send it back to the backend of our app.
We’ve calculated how much it would cost us to use this model (all calculations were done roughly and with a margin) and how cost-effective our choice was. when using the model for 22b parameters, if we put 1000 tokens per request, then there will be 0.002$ per input and 0.006$ per output. so if we assume that the model will perform 100 requests per day for 1000 tokens per input and output, then we get: 0.2$ per day per input and 0.6$ per day per output. Despite the fact that we’re using the biggest model (22B), we still have a strong trade-off between the cost and effectiveness of responses of 22B model. One additional advantage of this model is 64k context window which allows to scale our app, function calling which will us to integrate other APIs for requests and existence of json mode will us to handle responses of recipes in more convenient way. All those advantages made us choose this model to provide a strong and effective functionality for developers and users of our app.
Scalability and Performance: #
Our application is designed with scalability in mind to accommodate future growth and increasing user loads. The architecture utilizes microservices, allowing individual components to scale independently based on demand. This ensures that as user numbers grow, our system can expand without significant reconfiguration or downtime. To ensure our application maintains high performance under load, we implement performance optimization techniques at various levels of the stack.
Security and Privacy: #
Ensuring the security of user data is paramount. We are integrating robust security measures into our architecture to protect against potential vulnerabilities. We are implementing secure user authentication methods and ensuring secure integration with third-party APIs through secure API keys and tokens. Protecting user privacy and complying with data protection regulations are critical aspects of our project.
Error Handling and Resilience: #
Implementing robust error handling mechanisms is essential for maintaining a reliable application. We have defined strategies for logging, monitoring, and gracefully recovering from errors.
Deployment and DevOps: #
In our project, we have established a comprehensive deployment and DevOps strategy to ensure smooth development and reliable deployment of our application. We have set up a GitHub repository, which serves as the central hub for all our code and documentation. To maintain code quality and ensure collaborative development, we have implemented protection rules for our main branch. Any changes or additions to the main branch will require thorough reviews through pull requests before merging. Each team member is responsible for creating their own branch to work on new features or bug fixes. This practice helps in isolating changes and facilitates easy integration and testing. We will use Docker Compose for local orchestration of containers, allowing each developer to have a consistent and isolated development environment, mirroring the production setup as closely as possible. Additionally, we plan to publish the application in a container registry, ensuring that our deployment process is streamlined and that we can easily manage and deploy containerized applications.
Week 2 Questionnaire: #
Tech Stack Resources:
- Patterns of Enterprise Application Architecture
- Purpose: Provides comprehensive guidelines on designing robust enterprise applications.
- Utilization:
- Architecture Design: Enhance our understanding of designing scalable and maintainable backend systems.
- Best Practices: Implement industry-standard patterns to improve application reliability and performance.
- Complex Problem-Solving: Apply architectural solutions to address complex challenges in our application.
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
- Purpose: Offers practical guidance on building and deploying machine learning models using popular frameworks.
- Utilization:
- Model Development: Improve our proficiency in developing machine learning models for food recognition and recipe generation.
- Implementation Techniques: Gain insights into effective techniques for training and optimizing ML models.
- Integration: Learn to seamlessly integrate ML models into our application, enhancing its functionality with AI-driven features.
- Universal Principles of Design, Revised and Updated
- Purpose: Provides key principles and guidelines for creating user-centered designs.
- Utilization:
- User Interface Design: Apply design principles to create intuitive and user-friendly interfaces for our app.
- User Experience Enhancement: Focus on improving the overall user experience through well-thought-out design choices.
- Design Consistency: Ensure consistency and coherence in the visual and interactive elements of the application.
- Patterns of Enterprise Application Architecture
Mentorship Support:
- Currently, our project team does not have an actively involved mentor. We recognize the significant value a mentor could bring, including expert guidance in mobile app development and AI, resource utilization, networking opportunities, skill development, and enhanced problem-solving. To secure a mentor, we plan to reach out to professors, industry experts, and utilize online communities. Having a mentor would provide the expertise and support necessary to ensure the success of our product.
Exploring Alternative Resources:
- To expand our understanding of the tech stack for CookAInno, we’ve explored several valuable resources beyond project-based books. Online courses from platforms like Coursera, and Udemy have provided in-depth knowledge on Spring framework, Kotlin, Docker, Roboflow, and YOLO models. Additionally, we’ve leveraged official documentation for frameworks like Spring and Kotlin, along with industry blogs on Medium and Dev.to, to stay updated with best practices and detailed guidance. Video tutorials from YouTube channels such as “Tech with Tim” and “freeCodeCamp.org” also have offered practical insights into Python, Java, Spring Boot, and advanced Android development. These resources have been instrumental in filling knowledge gaps and enhancing our project development skills.
Identifying Knowledge Gaps:
- Within our tech stack division, there are identified knowledge gaps on the Backend side in JWT (JSON Web Token) authentication, particularly concerning understanding JWT structure, security best practices, and token lifecycle management like revocation and renewal. To address these gaps comprehensively, we’re planning targeted training sessions to explore Spring Security functionality, fostering peer reviews for code implementation, leveraging external resources for diverse perspectives, and establishing a culture of continuous learning and feedback. These initiatives aim to enhance team members’ proficiency in JWT authentication, ensuring robust security practices and efficient implementation within our applications.
Engaging with the Tech Community:
- As students embarking on a project to develop an AI-based application for fridge content recognition and recipe suggestions, we understand the importance of engaging with the tech community. Our approach will be to attend relevant meetups and university consultations where we can interact with professors and experts in the field. We plan to seek advice from university professors specializing in computer vision, backend, and Android development. Additionally, we will ensure thorough beta testing by collaborating with culinary enthusiasts and students, who can provide practical feedback on the app’s functionality. This engagement will not only enhance our learning experience but also contribute to the app’s success by including diverse perspectives and expert knowledge.
Learning Objectives:
- This week, our primary learning objective is to gain a comprehensive understanding of integrating AI and machine learning models within our tech stack. Specifically, we aim to deepen our knowledge of: image recognition, GPT API integration, and Docker for containerization. Additionally, we will continuously retrospect our decisions on the functionality of the application to ensure we provide users with a solid, usable product and the relative technologies to implement this. By employing these strategies, we aim to not only enhance our technical proficiency but also ensure the development of a robust and user-centric application.
Sharing Knowledge with Peers:
- Our approach to sharing knowledge and expertise within the team includes several strategies: weekly knowledge-sharing sessions and collaborative documentation.
Leveraging AI:
- To compensate for gaps in our technical expertise while developing, we leveraged AI by integrating AI-powered tools and platforms. We used AI-driven code assistance tools such as BlackBox AI to enhance our proficiency and streamline the coding process, ensuring efficient and effective implementation of the app’s features.
Tech Stack and Team Allocation #
| Team Member | Track | Responsibilities |
|---|---|---|
| Efim Puzhalov (Lead) | Backend, System Architect | Team management, project architecture, database access, backend integration with Android app |
| Egor Meganov | Frontend (Android) | Main Android app functionality |
| Vladislav Grigorev | Backend, DevOps | Authentication process, backend deployment |
| Renata Latypova | Design, ML | UI design, ML integration with Android app |
| Polina Pushkareva | ML | Recipe generation, user recommendation system |
| Milyausha Shamsutdinova | ML | Groceries recognition model |
| Aliia Bogapova | Design, Frontend (Android) | UI design, Android app functionality |
Weekly Progress Report #
Challenges and Solutions #
- Implemented functionality for storing and retrieving user data, ensuring efficient and secure data management.
- Developed comprehensive features for managing users’ favorite recipes, allowing full manipulation capabilities such as search by name, update, and other CRUD operations.
- Researched object detection models for a grocery image detection project. Evaluated several models, including YOLOv8, Faster R-CNN, and EfficientDet. Selected YOLOv8 for its optimal balance between accuracy and speed, crucial for real-time detection.
- Evaluation of model trained. The model shows good validation metrics for classes such as bell pepper, fasol, garlic, onion, hot pepper, and peas, as there are enough images for these categories. However, due to the dataset being very imbalanced and the underrepresentation of other classes, the model performs poorly on those less represented categories. This is evident from the lower mAP scores for these underrepresented classes. Therefore, we plan to expand the dataset by manually collecting and annotating additional data for these insufficiently represented classes to improve the model’s performance. There is a metrics:
| Classes | Images | Instances | Box(P) | R | maP50 | mAP50-95 |
|---|---|---|---|---|---|---|
| all | 96 | 390 | 0.87 | 0.861 | 0.887 | 0.642 |
| Apples | 4 | 4 | 0.881 | 0.75 | 0.912 | 0.607 |
| Bun | 4 | 7 | 0.778 | 1 | 0.995 | 0.593 |
| Cabbage | 2 | 2 | 0.788 | 1 | 0.995 | 0.698 |
| Cold Drink | 1 | 1 | 1 | 0 | 0 | 0 |
| Dry Fruit | 1 | 1 | 0.94 | 1 | 0.995 | 0.497 |
| Eggs | 1 | 1 | 0.407 | 1 | 0.995 | 0.796 |
| Green Seeds | 2 | 2 | 0.788 | 1 | 0.995 | 0.723 |
| Milk | 1 | 1 | 0.694 | 1 | 0.995 | 0.895 |
| Oil | 3 | 3 | 0.842 | 1 | 0.995 | 0.632 |
| Pineapple | 2 | 2 | 0.822 | 1 | 0.995 | 0.729 |
| Snacks | 2 | 5 | 0.9 | 1 | 0.995 | 0.788 |
| Vegetables | 3 | 3 | 0.91 | 1 | 0.995 | 0.734 |
| Water Bottle | 4 | 7 | 1 | 0.974 | 0.995 | 0.711 |
| bell pepper | 18 | 85 | 0.948 | 0.865 | 0.946 | 0.739 |
| bread | 3 | 4 | 0.892 | 1 | 0.995 | 0.65 |
| carrot | 1 | 2 | 1 | 0 | 0 | 0 |
| fasol | 18 | 24 | 0.886 | 0.917 | 0.94 | 0.796 |
| garlic | 18 | 86 | 0.908 | 0.807 | 0.935 | 0.609 |
| hot pepper | 9 | 28 | 1 | 0.811 | 0.934 | 0.685 |
| onion | 15 | 77 | 0.946 | 0.918 | 0.988 | 0.727 |
| peas | 10 | 30 | 0.77 | 0.767 | 0.806 | 0.514 |
| salad | 8 | 9 | 0.995 | 1 | 0.995 | 0.798 |
| tomato | 3 | 6 | 1 | 0.992 | 0.995 | 0.694 |
- No even a remotely suitable dataset for the ingredient detection model. Determined that creating a custom dataset was necessary, as no existing datasets fully met our needs. This realization presented a significant challenge.
- Successfully implemented authentication functionality on Android devices, ensuring secure user access through JWT and email confirmation.
- Drafted the camera screen interface, which will serve as the gateway for the machine learning component to recognize ingredients from photos.
- Developed a screen that presents a list of recipes, which includes recipe cards that load images from the internet. Organized these cards into a grid layout on the screen, providing an intuitive and visually engaging way for users to discover and browse through different recipes.
- Faced the challenge of selecting a modern LLM model for recipe generation. Evaluated four models (Gpt-4o, Mistral, Gemini, Claude) and selected Mistral (22b params) for its user-friendly API, good pricing per million tokens, multilingual capabilities, 64k context window, and native function calling capacities.
- Started implementing recipe generation using the Mistral API, including creating an account, obtaining an API key, reading the documentation, and writing the recipe generating function.
Future Work #
- Deploy the backend part and add new features according to calories management and user recommendations.
- Сreatе the custom dataset for object detection, starting with image sourcing and annotation. Train YOLOv8 with the created dataset.
- Integrate the camera screen interface with the backend and machine learning component to recognize ingredients from photos.
- Continue enhancing the user interface for recipe discovery, focusing on improving the visual appeal and functionality of the recipe cards.
- Complete the implementation of recipe generation using the Mistral API, refine the starting prompt for the model to set the context, and test the functionality to ensure it meets project requirements.