Match&Watch: Project Report for Week 3 #
Developing the First Prototype and Creating the Priority List #
Technical Infrastructure #
Each team has created a sub-repository with two branches: main and develop. These branches facilitate CI/CD integration and ensure all team members can access and contribute effectively. Additionally, each subteam has added collaborators from other teams to ensure smooth integration and collaboration. While these sub-repositories are for ease of working, the final result will be pushed into one central repository (the course org repo).
Data Management #
User Profiles #
- Schema: Stores user information.
Questionnaires #
- Schema: Stores information about each questionnaire, including questionnaire ID, title, description, creation date, and update date.
We used PostgreSQL as the database to manage and store this information.
Weekly Progress Report #
This week, we made significant progress. We implemented several features in both the backend and frontend. Additionally, we prepared a clear plan for the AI component, detailing the dataset, pipeline, and future steps.
Prototype Features #
Backend #
Endpoints for Questionnaires
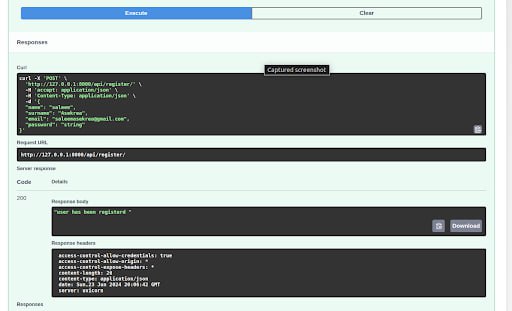
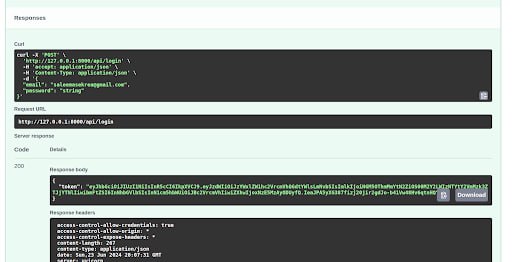
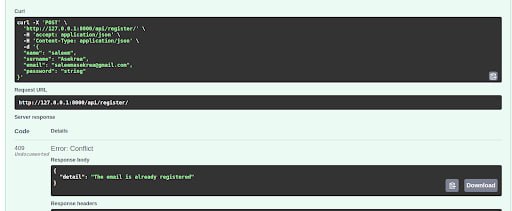
- Implemented CRUD operations (Create, Update, Delete) for managing questionnaires.
Store User Responses
- [Implement functionality to store user responses.]{.mark}
Testing
Load Testing
Stress Testing
Frontend #
Homepage
- Entry point for user registration and login processes.
Signup Page
- Implemented a straightforward registration form for new users.
Login Page
- Ensured secure login functionality with user credentials.
Questionnaire Page
- Created a page for users to answer one question with dummy movie matches.
User Interface #
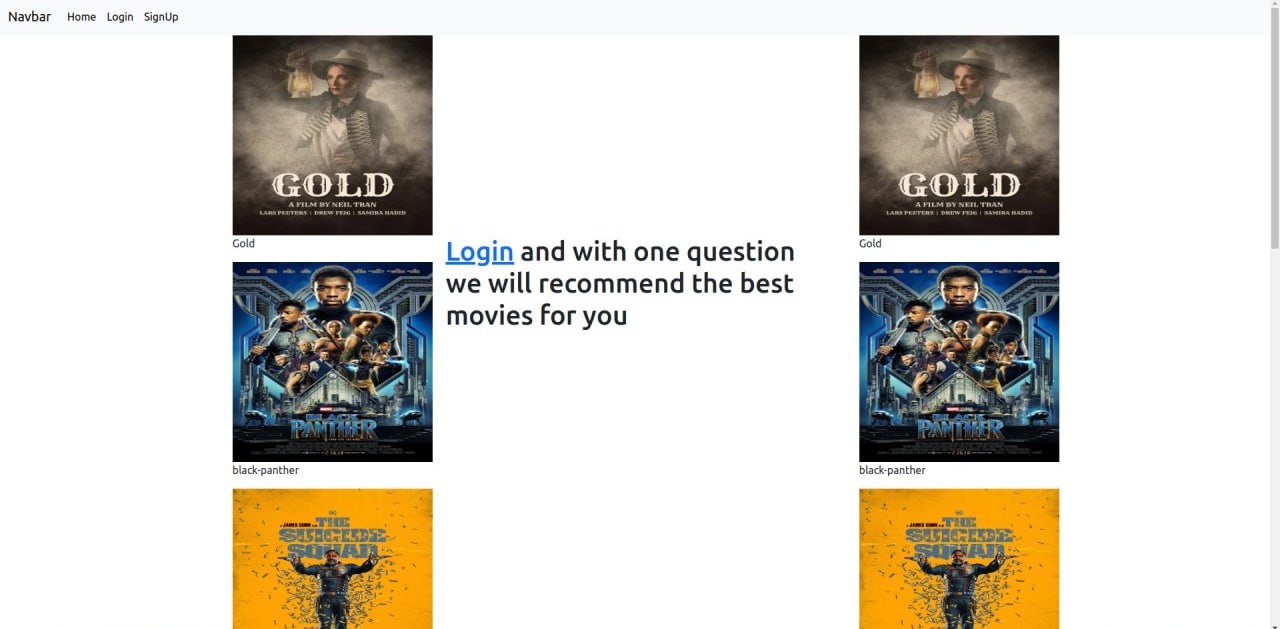
Homepage #
- Entry point for user login/signup.
Signup Page #
- Allows users to sign up using their email and create a password.
Login Page #
- Enables registered users to log in with their credentials.
Question Page #
- Users answer a questionnaire to receive personalized recommendations.
Challenges & Solutions #
AI Implementation #
In our AI implementation, we encountered difficulties finding a sentiment analysis model suitable for extracting nuanced emotions from movie descriptions or plots. Existing models generally provide basic positive, negative, or neutral sentiment analysis, which does not meet our need for detailed emotional analysis. Considering this, we are exploring the use of LLM (Large Language Model) models due to their advanced natural language processing capabilities, which we believe will better suit our requirements.
Frontend Framework Selection #
During the frontend development phase, our team faced challenges in selecting an appropriate framework. After careful evaluation, we decided to adopt Vue.js, despite its relatively new status. We believe Vue.js offers the flexibility and modern features necessary to deliver a user-friendly interface.
Conclusions & Next Steps #
Priority List #
High Priority
Backend:
Implement Password Recovery Functionality
Design Mood Tracking Data Model and Database Schema
Create Mood Tracking Endpoints (Submit and Retrieve Mood Data)
Develop API Endpoint for Mood Analysis Submission
Write Unit Tests and Integration Tests for Backend Functionality
Frontend:
Integrate all pages with the backend
Build a profile page for users
Machine Learning:
Extract emotions from movies and add it as a feature
Finalize the pipeline for the Recommendation System
Medium Priority
Backend:
Optimize Database Queries and API Endpoints for Efficiency
Store AI analysis results for personalized recommendations
Frontend:
- Improve design
Machine Learning:
- Start the model training for extracting embeddings from movies
Low Priority
Backend:
Implement Notifications and Alerts Based on Mood Analysis
Develop Endpoints for User Feedback and Rating System
Implement Feedback Collection and Analysis System