Week #3 #
Developing the first prototype, creating the priority list #
Technical Infrastructure: #
Currently, all the technical infrastructure for the prototype is ready. We deploy all microservices on remote virtual machines and support them using CI/CD. All pipelines run on self-hosted runners:
Since all microservices run in Docker containers, it is easy to add new functionality without the problems of changing server infrastructure:
We also follow the Git-flow approach in developing the code:
gitGraph commit branch api-server commit checkout main branch telegram-bot commit commit checkout api-server commit commit checkout main branch frontend commit commit checkout telegram-bot commit checkout main merge frontend merge api-server merge telegram-bot
To review code, we use pull requests: https://github.com/IU-Capstone-Project-2024/MoniDorm/pulls
Backend Development: #
The backend development is progressing rapidly:
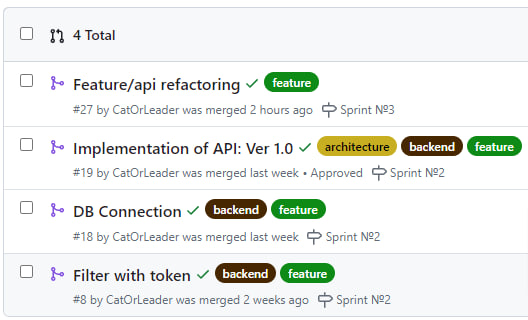
We designed 4 versions of API REST Contracts: API REST Contracts
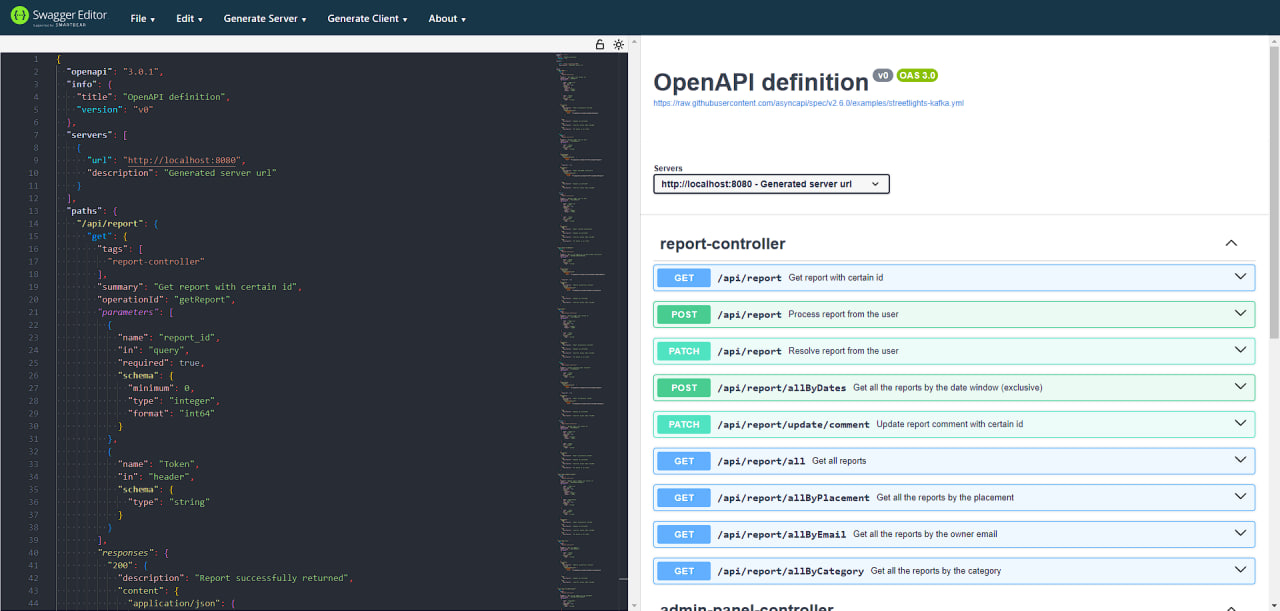
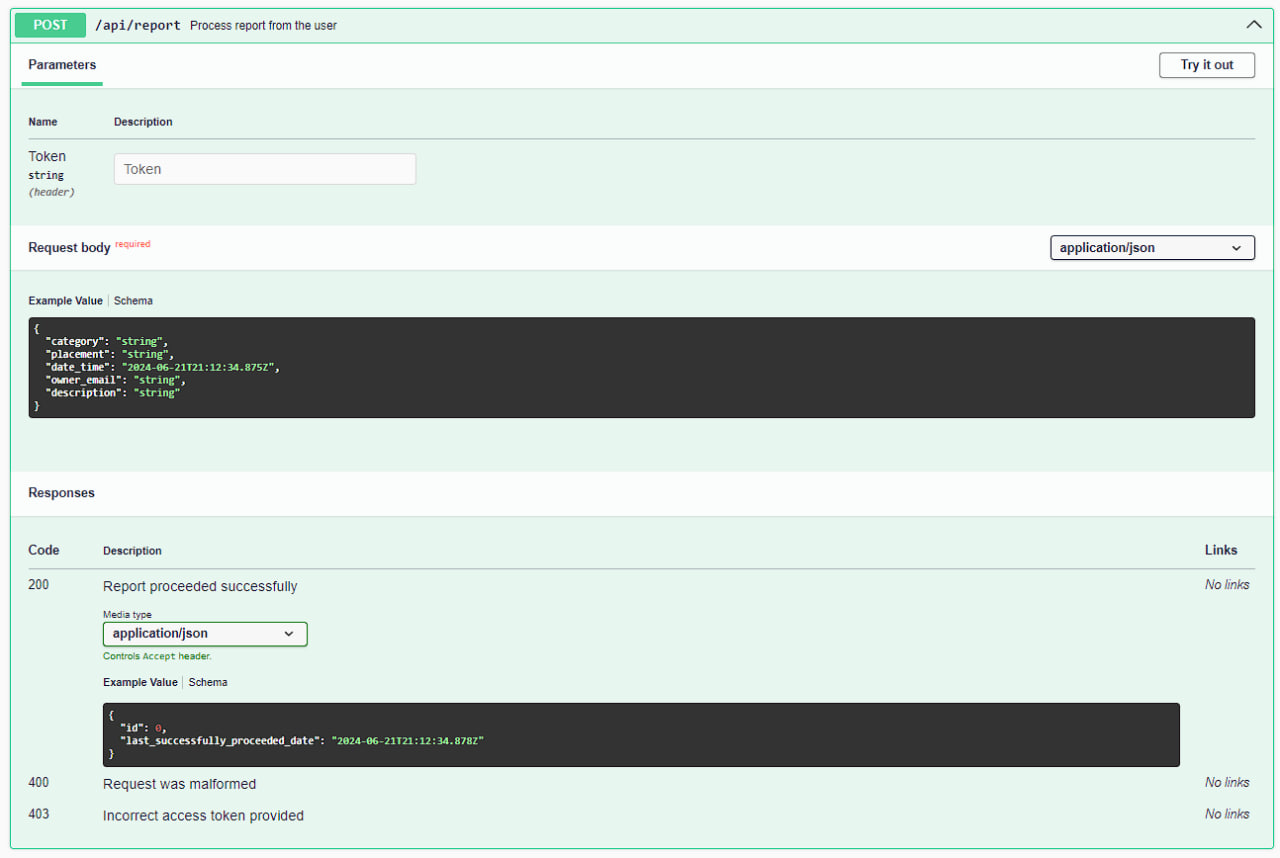
We have also started implementing them: Implementation PR
Later, we allocated time to refactor the code: Refactor PR
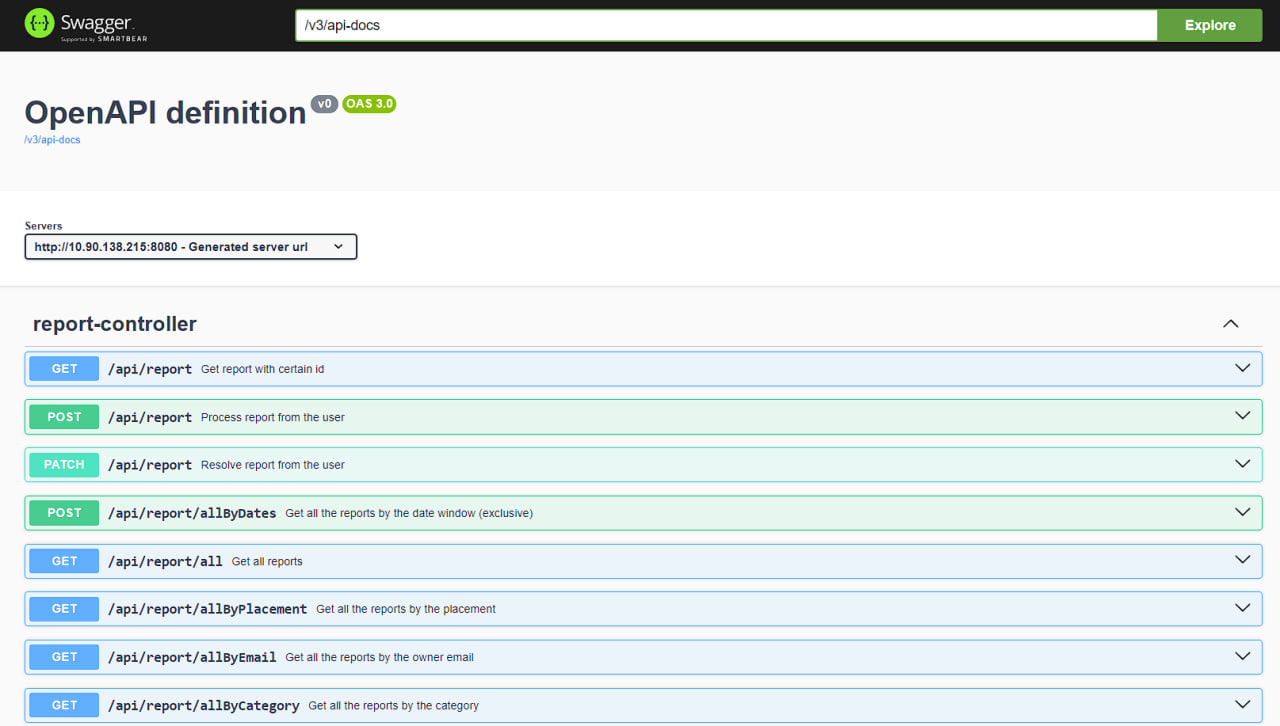
Now, the API is deployed and is being used by other services: API Swagger UI
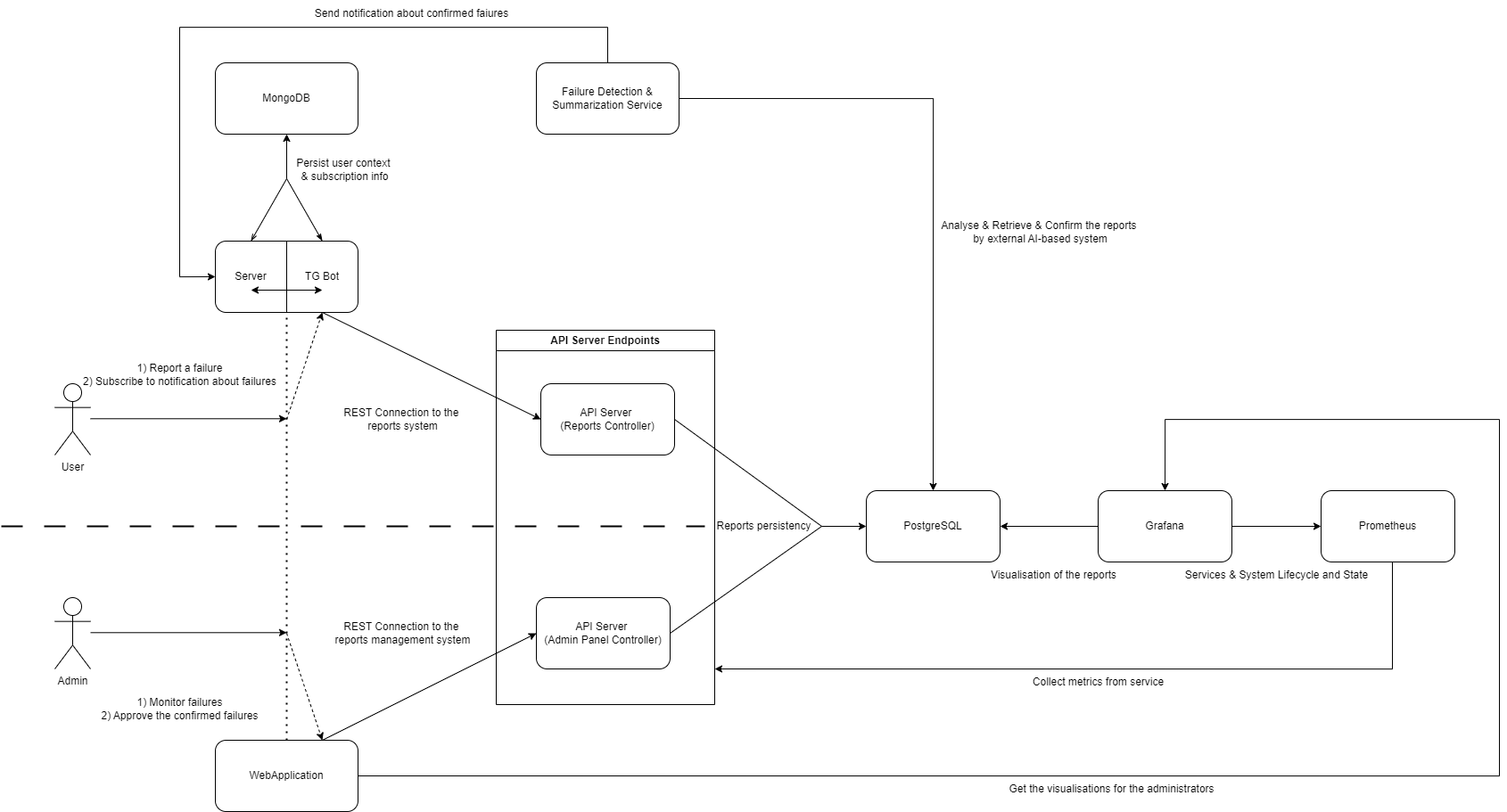
And we have also slightly reworked the Backend architecture scheme:
Frontend Development: #
For the Frontend development we have created a website with embedded Grafana visualization. For the future plans there is an idea to convert it fully to a Telegram Web App.
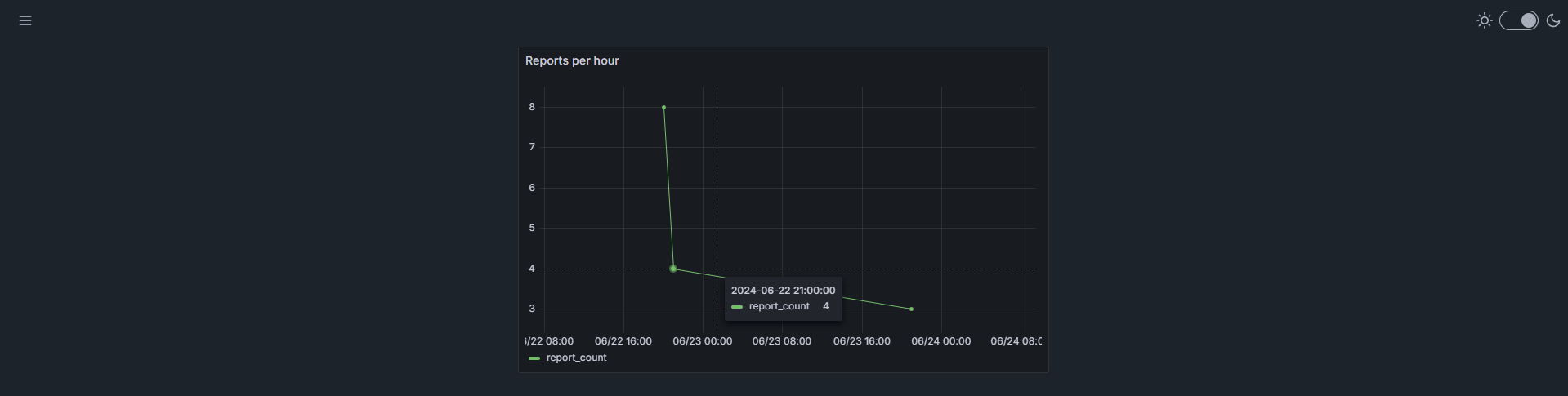
During the creation of the page we have faced some difficulties, but the most important is how to visualize data. We tried some methods, but the most successful was the embedded interactive Grafana dashboard, which you can see on the screenshot above. We plan to have a set of dashboards on the page, on which an admin can easily navigate and see detailed statistics.
Data Management: #
For data storage, we followed the plan outlined in our Week 2 report.
PostgreSQL:
Purpose: Store reports on dormitory infrastructure issues.
Basic Operations: Insert, update, retrieve, and delete reports.
CREATE TABLE IF NOT EXISTS report(
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
category varchar(128) NOT NULL,
placement varchar(128) NOT NULL,
failure_date TIMESTAMP WITH TIME ZONE,
proceeded_date TIMESTAMP WITH TIME ZONE,
owner_email varchar(128),
is_confirmed_by_analysis BOOLEAN NOT NULL,
is_confirmed_by_admin BOOLEAN NOT NULL,
is_resolved_by_user BOOLEAN NOT NULL,
is_resolved_by_admin BOOLEAN NOT NULL,
description varchar(256)
);
We use PostgreSQL for storing reports, adding data via API, and providing functionality for deleting and modifying certain fields (is_confirmed_by_analysis, is_confirmed_by_admin, is_resolved_by_user, is_resolved_by_admin, description).
MongoDB:
- Purpose: Store user information, including authentication details and roles.
- Basic Operations: Insert, update, retrieve, and delete user data.
The Telegram bot is connected to a MongoDB database, where it stores user emails, used commands, and other critical parts of the dialog.
Prototype Testing: #
We manually tested the prototype of the Telegram Bot according to the FSA Schema:
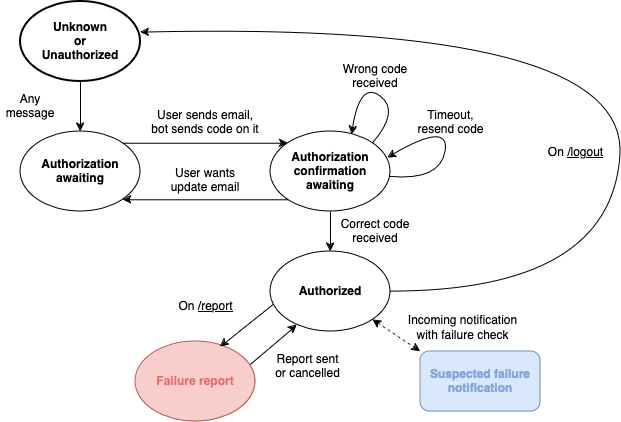
We concluded that it passes all states and transitions successfully, so now we rely on that information. Tests are completed every time after new features appear.
Backend API is tested automaticaly in CI/CD pipeline with unit and integration tests:
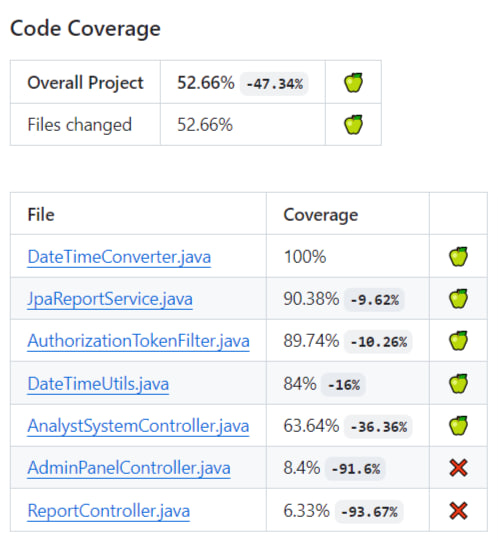
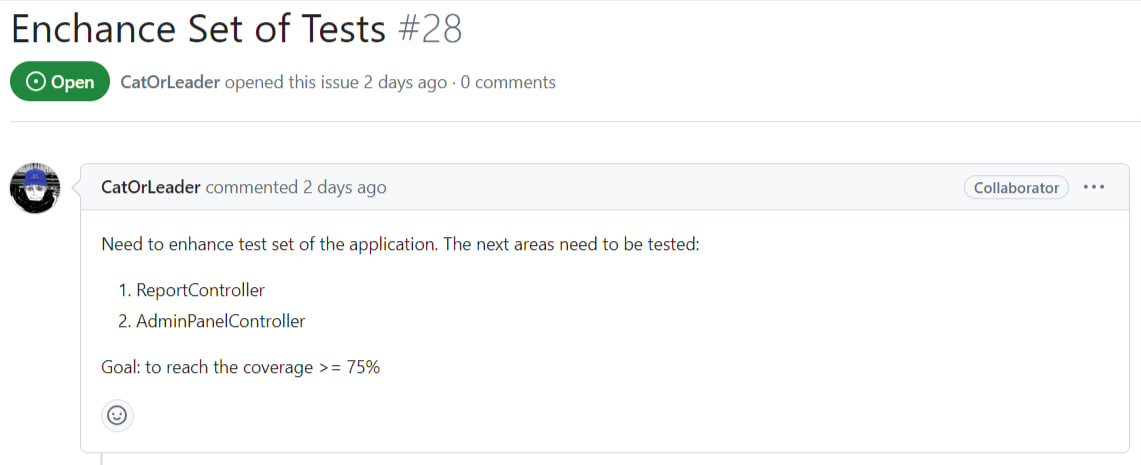
Although we goal to enhance test set and to reach the coverage >= 75%
LLM model research: #
OpenAI’s GPT-4 ( useful link )
This model can create human-like text and generate creative and coherent sentences.It is also capable of writing summaries by understanding and paraphrasing content, generating new sentences. ChatGPT participates in human-like dialogs by answering questions and maintaining context in interactions. It can also translate text from one language to another with a high degree of fluency.
Advantages:
- Versatility: Ability to handle a wide range of tasks beyond summarization.
- Quality: Generates human-like text, often producing coherent and fluent summaries.
- Contextual Awareness: Excellent understanding of the context and nuances of text.
Disadvantages:
- Cost: Large computational resources and costs associated with use and fine-tuning.
- Data privacy: Potential data privacy issues with cloud-based models.
- Length Limitation: Limited contextual window, which can be problematic for very long documents.
Google’s BERT (Bidirectional Encoder Representations from Transformers) ( useful link )
This model is adept at understanding the context of a word in a sentence, paying attention to the words before and after it. It also identifies and extracts key sentences from a document to create a summary. Moreover, it answers questions based on a given passage, used in search engines and chatbots. It is able to categorize text into categories, identifies proper nouns and specific information in the text.
Advantages:
- Contextual embeddings: Captures bidirectional context, leading to better text comprehension.
- Transfer Learning: Pre-training on huge amount of data, ability to fine-tune for specific tasks.
Disadvantages:
- Extractive generalization: Generally better suited for extractive rather than abstract generalization.
- Resource intensive: Requires significant computational power for fine-tuning and inference.
T5 (Text-to-Text Transfer Transformer) by Google ( useful link )
This model treats all NLP tasks as transforming input text into output text, making it very versatile. Also like previous systems it generates new, coherent summaries from text. It provides answers to questions based on given passages, translates text from one language to another, and is able to categorize text into given categories.
Advantages:
- Unified framework: Treats all NLP tasks as text-to-text transformations, simplifying training and model deployment.
- Abstract summarization: Particularly strong at generating new, coherent summaries.
Disadvantages:
- Resource intensive: High computational requirements for fine-tuning and inference.
- Fine-tuning: Requires careful fine-tuning to achieve optimal performance for specific tasks.
Pegasus by Google ( useful link )
Specially designed for summarization, the model excels at generating concise and informative summaries and efficiently handles and summarizes long documents. Moreover, it generates coherent and contextually appropriate text.
Advantages:
- Specialization: Designed specifically for abstract summarization, resulting in high-quality summaries.
- Handling long documents: Particularly effective for summarizing long documents. Disadvantages:
- Limited specialization: May not be as versatile for other NLP tasks.
- Training cost: high computational cost for training and fine-tuning.
Abstractive Summarization models (Pointer-Generator Networks) ( useful link )
This model generates new sentences to create a coherent and concise summary. It can manage non-vocabulary words using a pointer mechanism. Moreover, it combines extractive and abstractive methods to improve performance.
Advantages:
- Creativity: Can generate new sentences, resulting in more natural summaries.
- Coherence: Tends to create more cohesive and fluent resumes.
Disadvantages:
- Complexity: More complex learning models and processes.
- Resource intensive: Requires significant computational resources.
Multimodal Models (CLIP by OpenAI (for image-text tasks)) ( useful link )
This approach can understand and integrate both text and images. It matches text descriptions with corresponding images. It can also potentially summarize content that includes both text and images. Moreover, it can search images based on text queries and vice versa.
Advantages:
- Versatility: Can handle multiple data types, providing comprehensive summarization.
- Innovative: Applies to tasks using text and other data types, such as images.
Disadvantages:
- Specialization complexity: Specialized training data may be required for effective generalization.
- Complexity: More complex implementation and fine-tuning for specific tasks.
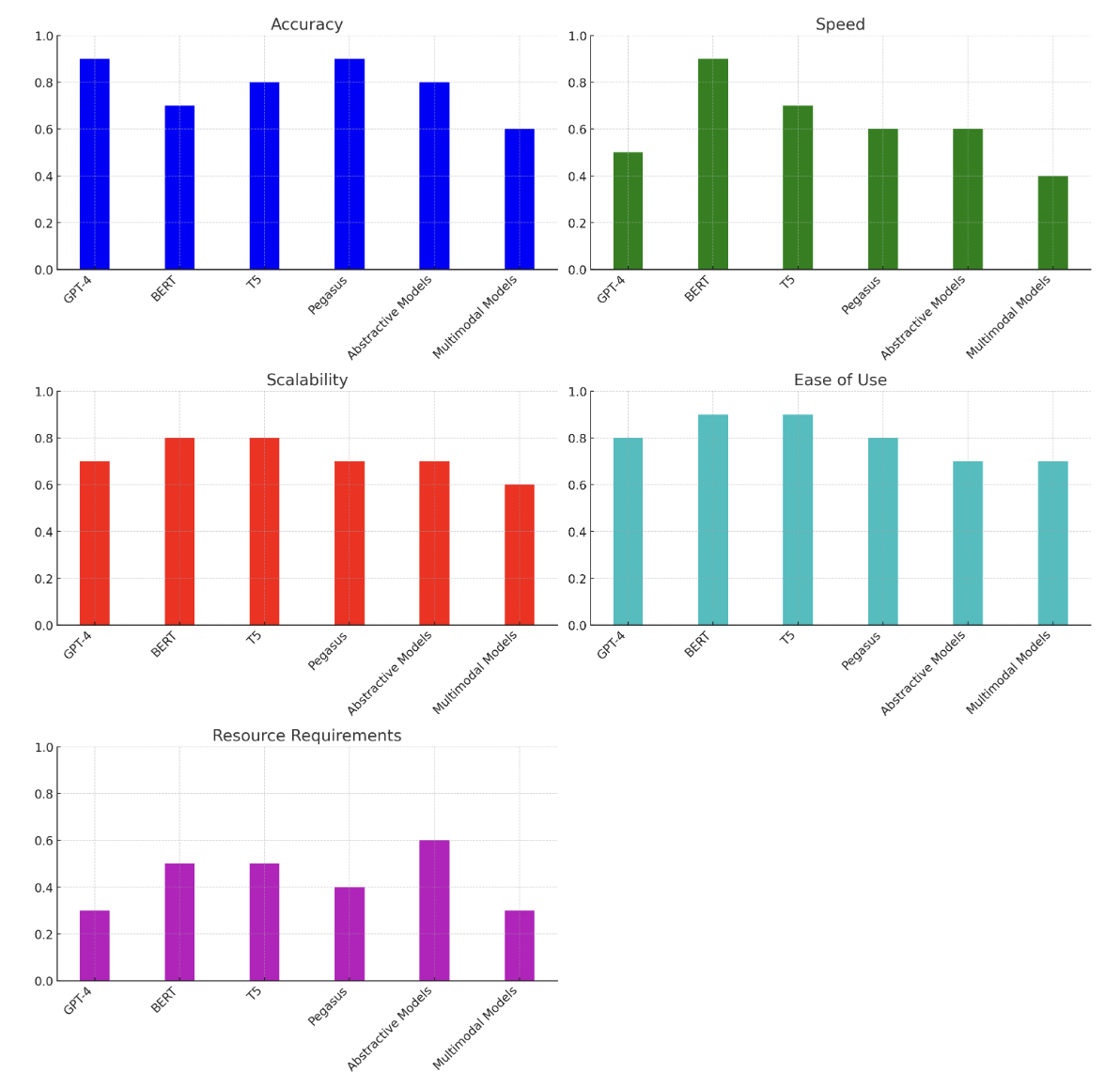
Conclusion:
- For High Accuracy: GPT-4 and Pegasus are ideal.
- For Speed: BERT is the best choice.
- For Scalability and Ease of Use: BERT and T5 are highly recommended.
- For Moderate Resource Requirements: BERT and T5 are more efficient.
- For Complex, Multimodal Tasks: Multimodal Models, though resource-intensive, are necessary for integrating text and image data.
Progress report: #
Prototype Features: #
We made significant progress on our prototype this week, focusing on backend development, frontend development, and data management:
- REST API Contracts: We developed four versions of REST Contracts APIs to define clear interactions between services. We have successfully implemented and deployed these APIs, which are currently being used by other services. The API Contracts ensure consistency and reliability across the system.
- Website with embedded Grafana visualization: Created a website with an embedded interactive Grafana data visualization dashboard. This dashboard allows administrators to easily navigate through various metrics and statistics. Future plans are to convert the website into a full-featured Telegram web app to increase accessibility.
- Telegram bot for sending reports: We created a bot that accepts reports from users. The bot is already connected to a MongoDB database to store all the necessary user data, such as email and dialog details. This feature allows for a convenient user-system interaction.
- Configuring and connecting the database to API for storing reports: Utilized PostgreSQL for storing reports on dormitory infrastructure issues. Implemented basic CRUD operations (Insert, Update, Retrieve, Delete) for managing reports.
Additional weekly work: #
- Code Refactoring: Allocated time to refactor the code for improved maintainability and performance. The backend architecture has been slightly reworked to accommodate new features and enhance scalability.
- Docker progress: Integrated Docker into our CI/CD pipelines, allowing for automated building, testing, and deployment of Docker images. This automation accelerates our development cycle and reduces the risk of human error.
- LLM Model Reaserch: A small study was done to identify the most appropriate language model for further use in analyzing the reports.
User Interface: #
The project is mainly focused on the backend and data management. However, the built-in Grafana dashboard on our website provides a visual representation of the data for admin users. There is also a user-friendly interface for the user, which is implemented through a Telegram bot.
Challenges and Solutions: #
Challenges:
Data Visualization: One of the major challenges was how to effectively visualize data on the frontend. Initial methods proved insufficient for our needs.
Backend Refactoring: Ensuring that the refactored backend code maintained functionality and performance was a complex task.
LLM model comparison: While searching for the best model to analyze the reports, it was difficult to know which model was better.
Solutions:
Grafana Dashboard: By embedding an interactive Grafana dashboard, we managed to overcome the visualization challenge. This approach provided a flexible and powerful way to present data.
Iterative Refactoring: We approached backend refactoring iteratively, ensuring that each step was thoroughly tested and validated. This minimized disruption and maintained system stability.
Use of articles and graphs: Graphs were constructed with data taken from articles to make a visual comparison.
Next Steps: #
- Convert the current website to a Telegram Web App to enhance user engagement and accessibility;
- Add more dashboards to the Grafana visualization for detailed insights;
- Add notifications first for all users when a failure is found, and then implement subscriptions to specific locations in the building;
- Implement an algorithm to search for failures based on reports;
- Add a LLM model to the system to summarize all reports and identify a single problem at a particular location;
- Continue refining API endpoints and improving performance;
- Enhance test coverage to achieve >= 75% to ensure robust;
- Automate more tests within the CI/CD pipeline to cover new features.