Week #3 #
Developing the first prototype, creating the priority list #
- Technical Infrastructure:
As our team got comfortable with the code of the project, we understood that machine learning models took too long to train on our personal computers. As such, we will be using the YandexCloud computing capabilities to save time and our laptops. Additionally, it has a service called Yandex Tracker, which helps us distribute tasks in the team. The rest of the project doesn’t require any special infrastructure, except for possibly opening a website on its own server once its time to present our work.
- Backend Development:
As per the last weeks goals, our focus was getting the basic model pipeline running. In order to get first results quicker, we decided to use Streamlit. In the end, we completed most of the pipeline, which includes: image captioning, image segmentation, prompt writer and diffusion model. The only model left to implement is the background labels predictor, which is mostly an additional feature and not required for the prototype to function properly.
- Frontend Development:
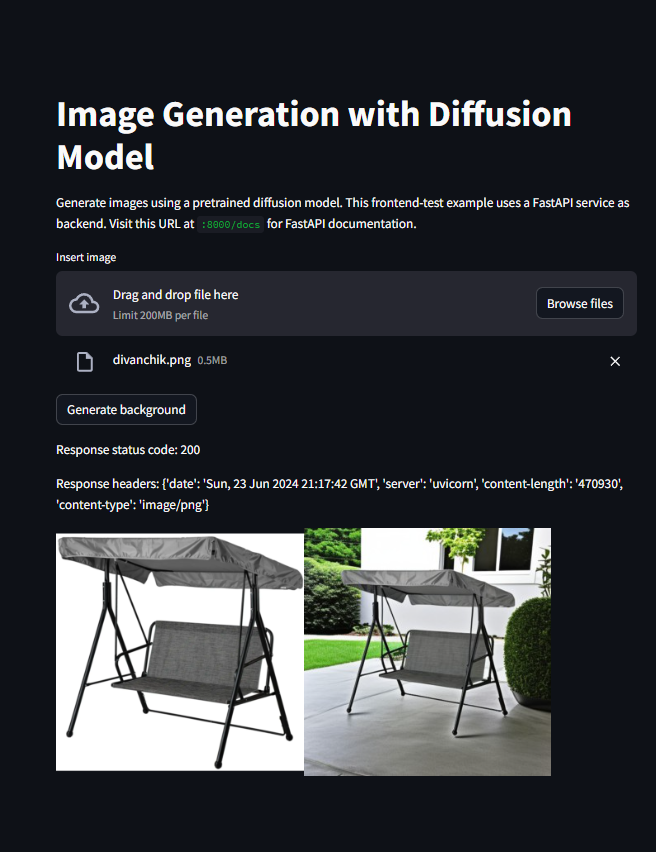
Developed the first iteration of the website with the basic features, such as accepting requests, sending requests to the backend and displaying the results.
- Data Management:
As we had a dataset available from our customers, we expanded and applied preprocessing to it to get more efficient model training. As for the database that stores the clients and their history, we plan to implement it in future weeks.
- Prototype Testing:
The prototype was collectively tested by us on a number of subjects, which showed us the areas that needed attention, mainly the prompt generation and glitches.
Examples of different generation results



Weekly Progress Report: #
Challenges & Solutions #
Yandex GPT prompts being hard to work with.
Solution: lots of experiments and general reading in the topic of prompts.Too many artifacts.
Solution: writing negative prompts for Stable Diffusion.UI breaking in different screen resolutions.
Solution: reading about the solutions and asking other developers both in the team and from the Leroy Merlen.Difficulties in parsing data due to the security measures of the Leroy Merlin website.
Solution: a script was written to transfer the necessary cookies (taking them from the browser) and parsing using BeautifulSoup
Conclusions & Next Steps #
Our team implemented the backend and frontend, assembled a pipeline of models and prepared the dataset for further training. With all of this in mind, our next steps are:
- development of background labels predictor architecture, and its training;
- connection of frontend and backend;
- improve the promts;
- adding new features like style selection and the number of generated images.