Week #2 #
Week 2 - Choosing the Tech Stack, Designing the Architecture #
Tech Stack Selection #
Desktop App: We will use Compose Multiplatform for A-Shot, as it is an easy-to-use and efficient tool for creating multiplatform applications.
Neural Networks: PyTorch will be our choice for training and operating neural networks due to its extensive toolset.
Image Handling: For loading images, we will opt for ImageMagick, as it supports over 100 image formats, including those preferred by photographers but not supported by common libraries like OpenCV.
Architecture Design #
Component Breakdown: A-Shot is composed of several key elements:
Multiplatform Desktop Application: This is the user-friendly interface that photographers interact with.
Machine Learning Modules:
Blur Detection: This module identifies and flags blurry images.
Similar Shot Grouping: This module groups similar shots together.
Data Management: A-Shot is optimized for handling large image volumes efficiently, maximizing performance and resource utilization.
In-Place Sorting: Images are organized within their original directories, offering disk space conservation and maintaining a streamlined, user-friendly file structure.
Thumbnail Generation: For fast operation and low memory usage, A-Shot displays thumbnails of high-resolution images within the user interface.
User Interface (UI) Design: The UI design is ready and available on Figma. The application consists of several screens, here are some of them:
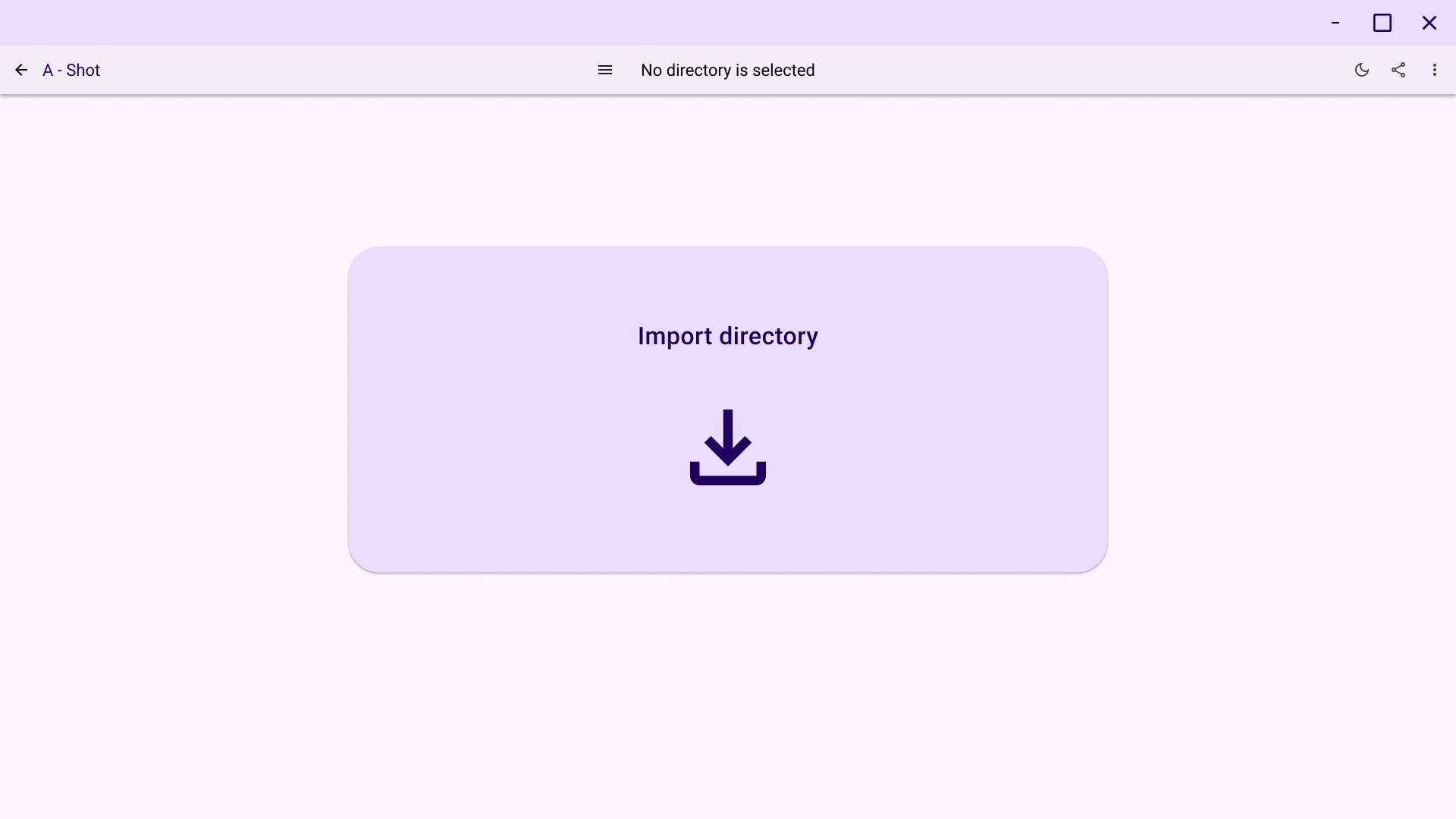
Import Screen: The initial screen for selecting the image source.
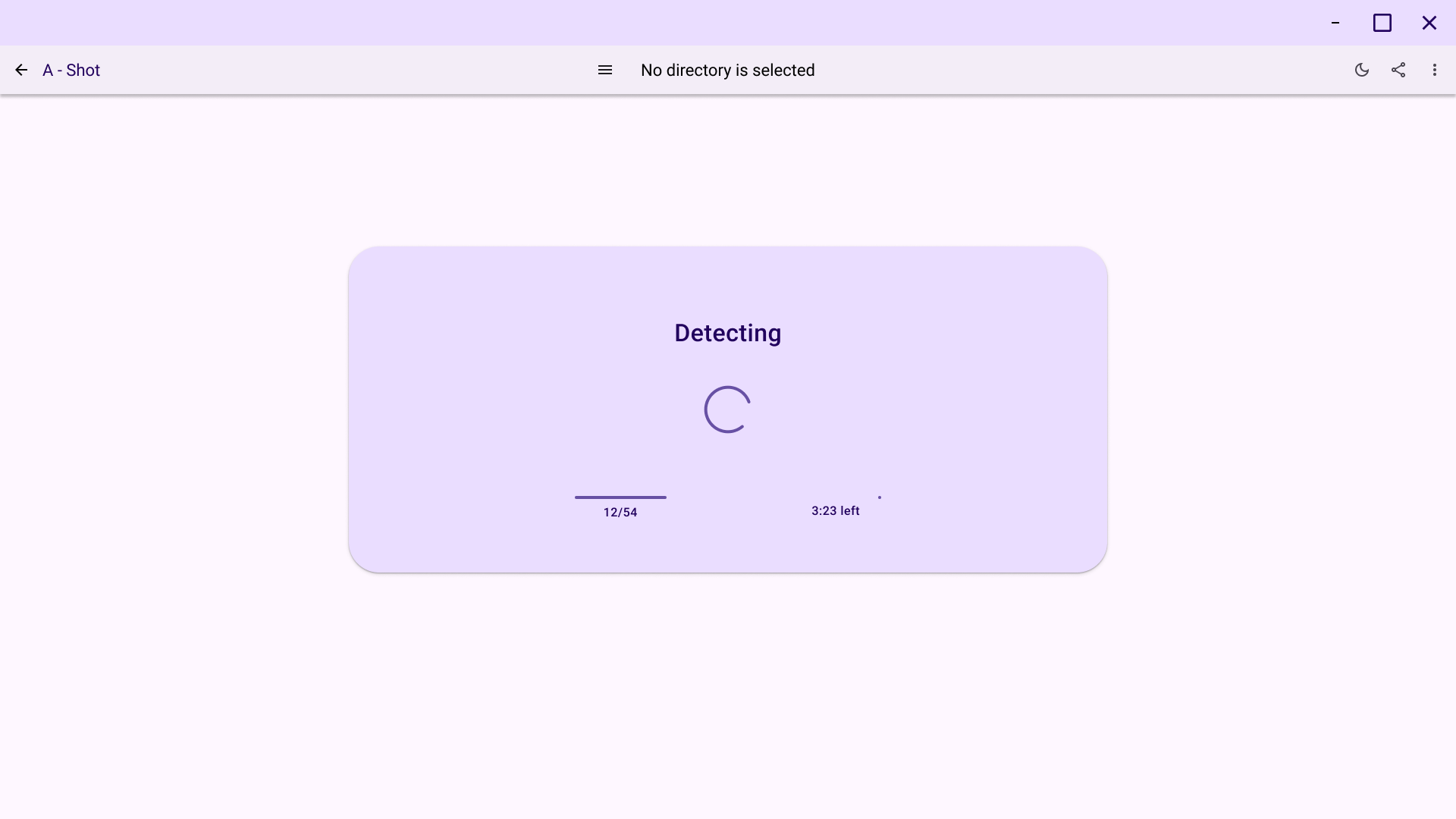
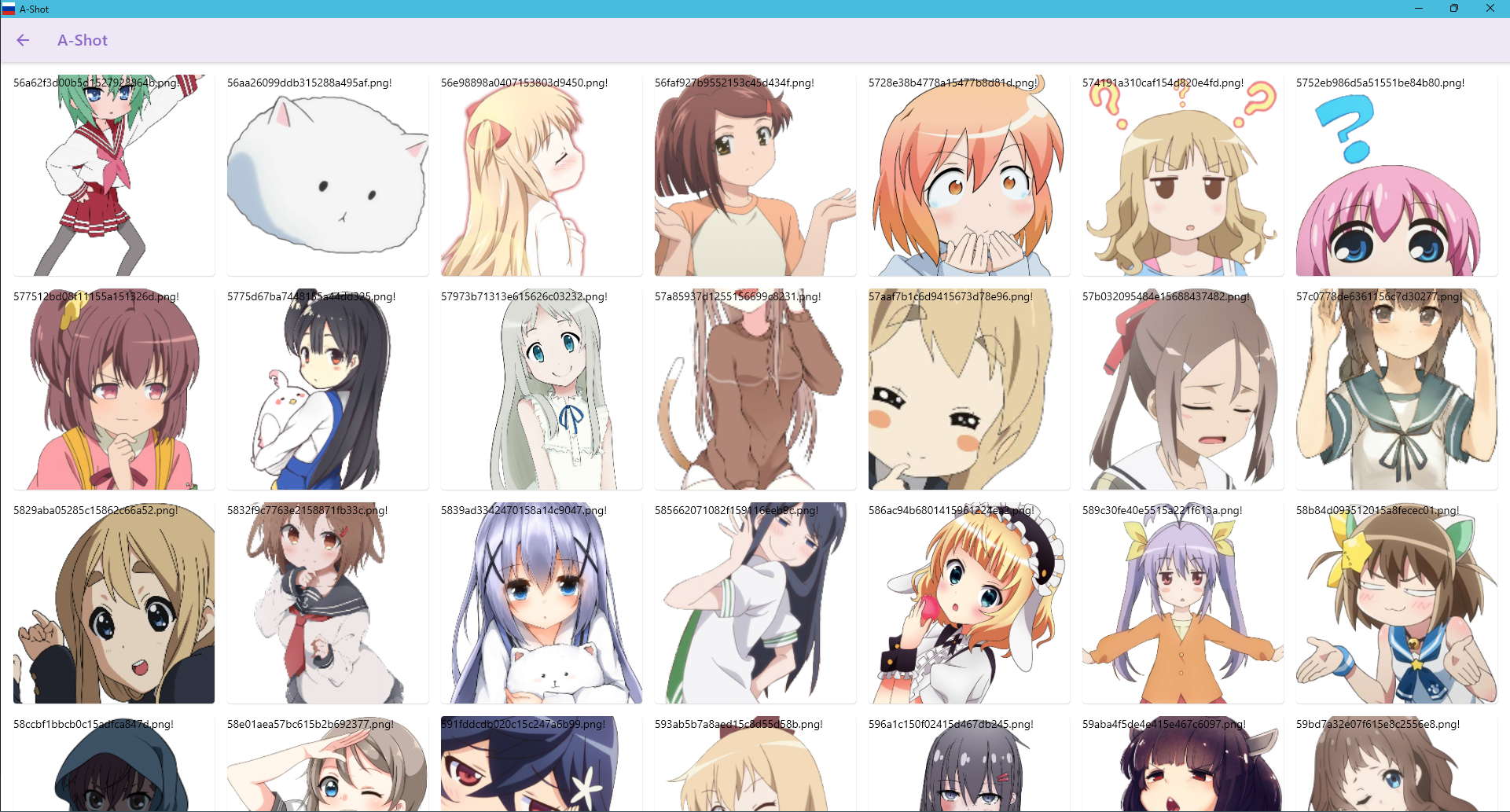
Overview Screen: Enables navigation between sorted shots.
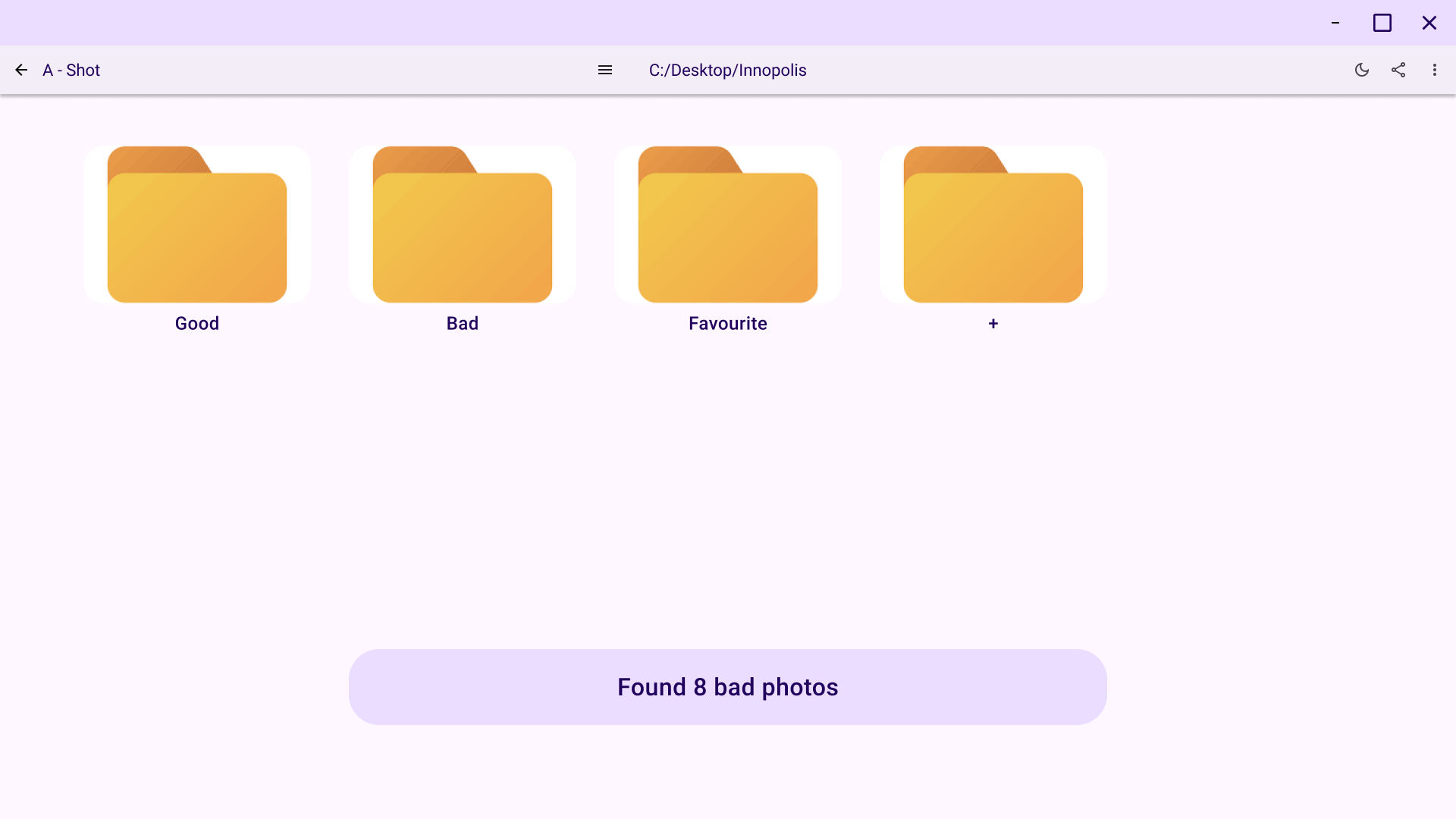
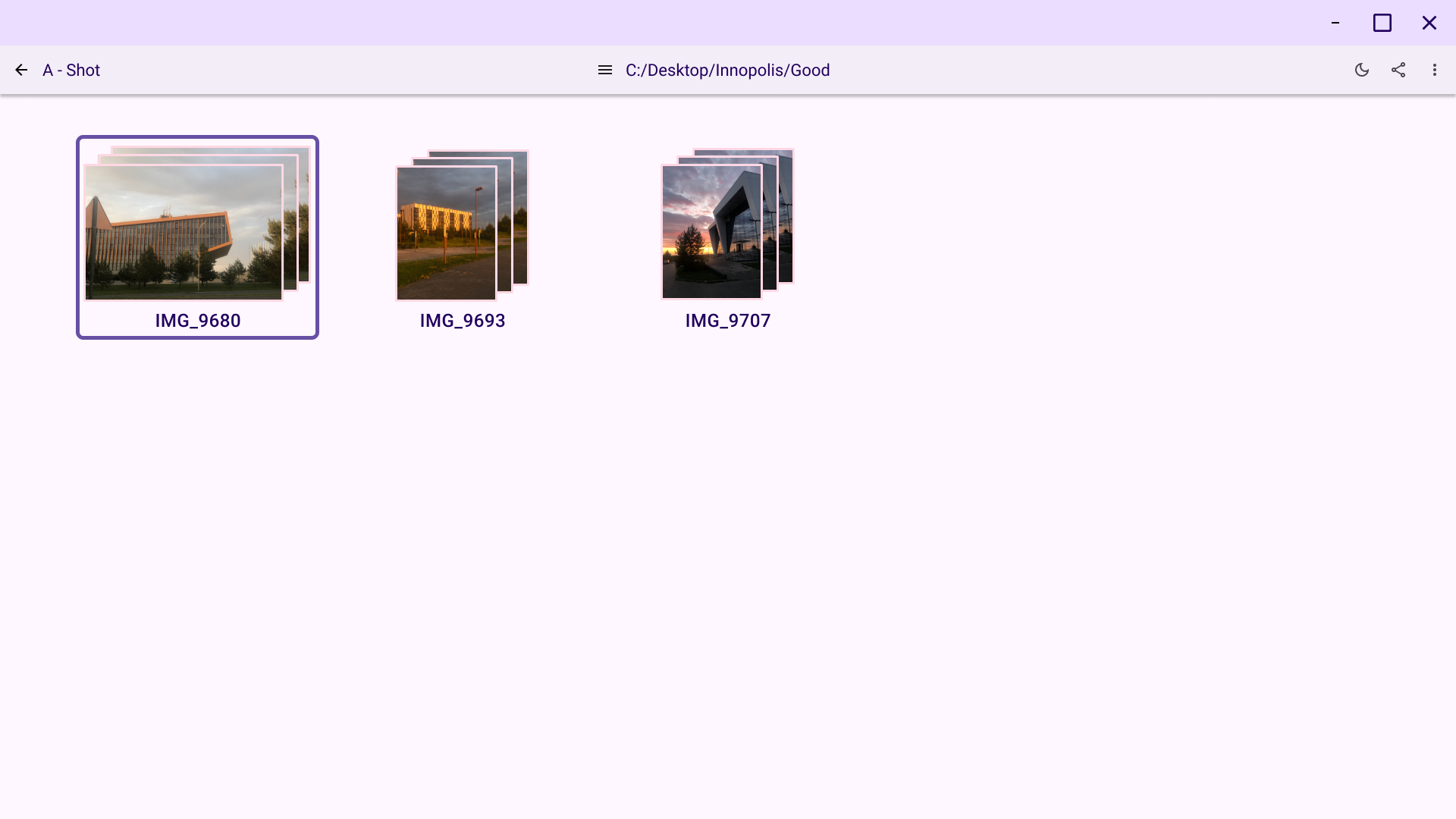
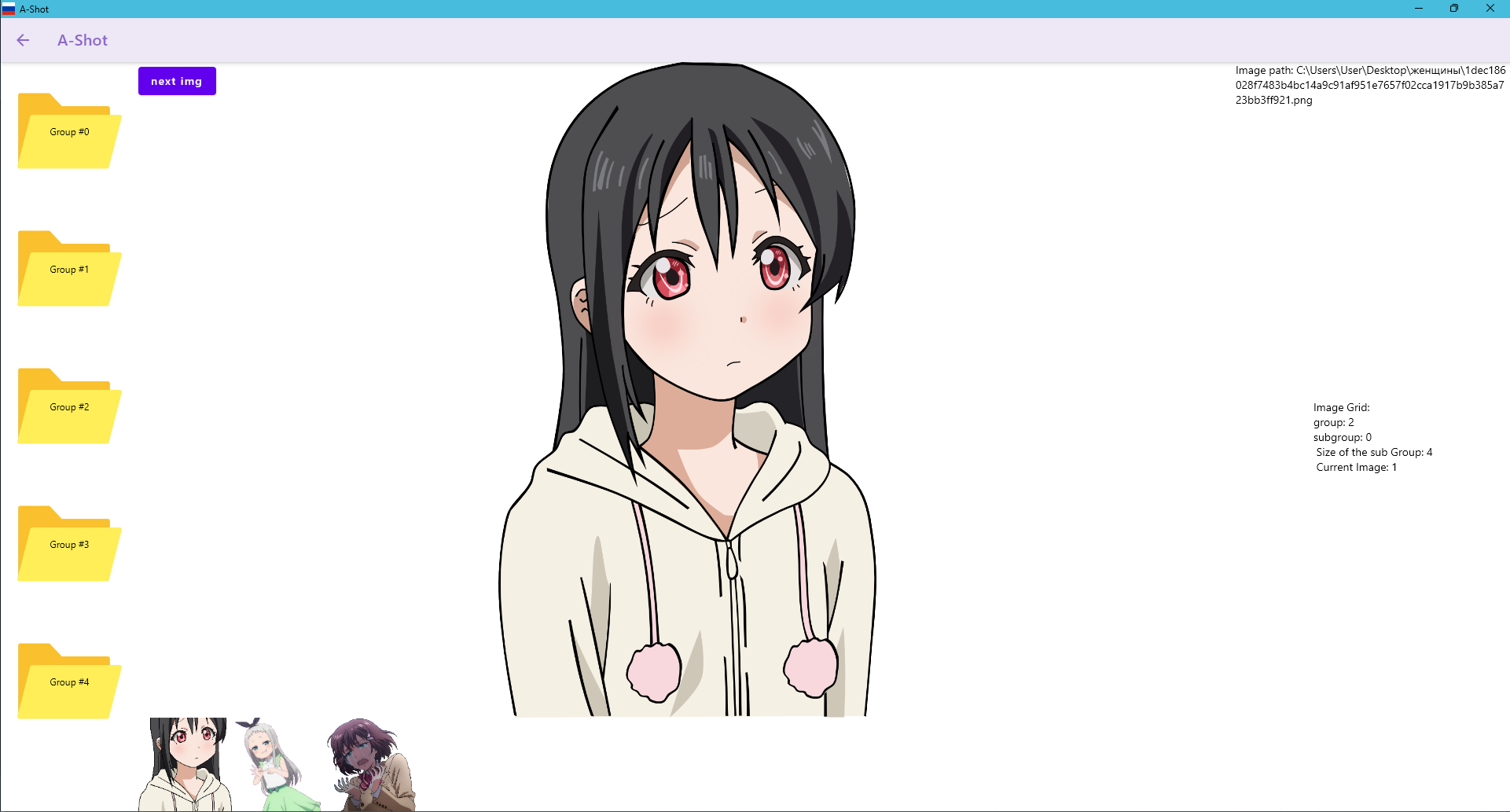
Cull screen: The core application interface for viewing grouped images and selecting the best ones.

Integration and APIs: A-Shot currently operates as a standalone application, performing model inference locally. Additional features may include integration with popular tools such as Adobe Lightroom and Adobe Photoshop, once the core functionality has been fully developed and optimized.
Scalability and Performance: A-Shot’s standalone nature and Jetpack Multiplatform development ensure effortless scalability across nearly all PC/laptop platforms. However, machine learning models should be optimized for efficient execution on lower-spec devices.
Security and Privacy: A-Shot ensures user privacy, as it operates offline without storing sensitive data.
Error Handling and Resilience: A-Shot prioritizes user data safety by avoiding sensitive operations like modification or deletion, ensuring that application errors do not affect user images. Furthermore, A-Shot will undergo testing under various conditions to guarantee reliability and resilience.
Deployment and DevOps: A-Shot’s CI/CD pipeline, using GitHub Actions, will ensure regular updates with automated testing, version control, and build processes. Deployments will be managed through GitHub Releases for seamless distribution.
Week 2 questionnaire: #
Tech Stack Resources: Our team utilizes the following tool documentations:
Mentorship Support: We are supported by Vladimir Bazelevich, a master’s student skilled in mathematics and machine learning (ML), who will help us navigate potential ML challenges.
Exploring Alternative Resources: In addition to documentation, we use websites like StackOverflow and LLMs ( ChatGPT, Chat Mistral). For ML solutions, we refer to Papers With Code, Google Scholar, and search engines.
Identifying Knowledge Gaps: Given the evolving nature of ML, we acknowledge the existence of knowledge gaps, especially when dealing with problems that traditional algorithms cannot solve. For instance, we plan to use siamese networks for image grouping, a method that has yielded satisfactory results in similar tasks. However, we are open to exploring new techniques or insights to enhance performance. An example of this is providing a model with depth insight to detect defocus blur, which resulted in improved performance. To assess our ideas and gain valuable insights, we will consult our mentor.
Engaging with the Tech Community: We actively follow GitHub, Papers with Code, and Google Scholar to keep up with the latest ML developments.
Learning Objectives: Our goals include:
- Gaining hands-on experience in machine learning, particularly within the context of image processing and analysis.
- Experimenting with novel methods for blur detection and similar shot grouping.
- Enhancing our team collaboration skills through the joint implementation and publication of a user-friendly ool.
Sharing Knowledge with Peers: We regularly discuss relevant topics, share solutions, and brainstorm ideas in our Telegram group and calls.
Leveraging AI: We employ AI tools like ChatGPT and Chat Mistral to gain clarity on technical aspects.
Tech Stack and Team Allocation #
| Team Member | Track | Responsibilities |
|---|---|---|
| Artemii Miasoedov (Lead) | ML | Product and Project management Blur detection |
| Timofey Brayko | ML | Image grouping |
| Artur Rakhmetov | ML | Image grouping |
| Nikita Kurkulskiu | ML | Desktop app |
| Egor Valikov | Cybersecurity | Desktop app |
| Matthew Rusakov | Software Development | UX/UI design, Desktop app |
| Mikhail Romanov | ML | Blur detection |
Weekly Progress Report #
During this week our team:
Completed the desktop app UI design: After completing the user flow and UI sketch, Matthew created Lo-Fi and Hi-Fi UI designs in Figma. The designs were evaluated by other team members, all required improvements were done. His work will be used in the following weeks to implement the desktop application.
Implemented UI drafts in demo desktop app: Nikita used UI sketches to create a demo application. The application contains all required screens and transitions between them. Moreover, application successfully runs both on Windows and Linux. Artemii helped to implement image caching and loading.
Import screen:
Overview screen:
Cull screen:
Identified existing solutions for blur detection and image grouping:
- Arthur and Timofey looked for existing image similarity ranking methods. They have found several solutions and identified the most promising works:
- Michael and Artemii checked papers on blur detection, highlighting the following ones:
Found datasets that can be used for training:
Identified required tools and libraries.
- Egor helped to find the library for image manipulations.
Challenges & Solutions #
Several challenges were identified during this week:
Blur detection:
- The first solution for blur detection primarily focuses on defocus blur detection. The accuracy of motion blur detection has yet to be determined. Furthermore, the code is provided without model checkpoints, meaning the model needs to be trained. The second paper claims to detect both types of blur, but no code is provided, making it impossible to evaluate quickly. Therefore, we plan to train the model from the first paper and use it in the MVP.
- Both methods only identify blurred areas, not distinguishing between harmful or benign blur (like bokeh). Classifying based on the size of the blurred area isn’t effective. Large blurred regions can be present in good bokeh shots (focused subject with a blurred background), and small blurred areas don’t necessarily mean a good photo (unsuccessful bokeh with an unfocused subject and focused background). A potential solution is to train additional neural network to distinguish harmful and benign blur maps. However, right now a more practical solution is to remove the images with extremely high blur areas, for example, 90–100%.
Image grouping: The promising model for image retrieval was trained on Landmarks, Oxford, and Paris datasets, which consist mostly of building pictures. This means it is highly likely that we will need to retrain these models on the datasets we have found.
Image caching: High-resolution pictures are quite large and take up a lot of time to load and memory space. This week, a demo solution was implemented in which large pictures are cached, and lighter versions are used in the future. This results in improved app performance.
Conclusions & Next Steps #
Throughout this week, we have determined the final view of the application and identified potential machine learning solutions to use. As the minimum viable product (MVP) is due next week, we do not have enough time to conduct extensive experiments. Currently, Artur, Timofey, and Mikhail will focus on adapting existing solutions and training them on custom datasets. In parallel, Nikita, Egor, and Matthew will work on the desktop application.