Week #2 #
Week 2 - Choosing the Tech Stack, Designing the Architecture #
Run-up #
This project is the logical continuation of our structure from the course of System and Network Administration. After reconsidering the tech stack we found that structure to be sufficient for this course, too.
Tech Stack Selection #
Our project will be built using Kubernetes, as it provides enormous scalability and resilience, and is relatively easy to deploy. As all of our team members are familiar with Python, we will be using it to implement both the web application and the task-assignment part of the testing container. As the tasks need to be tested in various languages with little overhead, we use Bash to launch the users’ code and time its execution.
As for the database, more justification is below, but in short, MongoDB was chosen as the primary database because it easily integrates with Python and it uses JSON format entries which allow for a bit more complex entry structures. Also, Redis was chosen for the work queue (of tasks that need to be tested) for its multiple access, security and timeout capabilities, as well as also easily integrating with Python.
For the webpage we will be using Flask, as it is one of the easiest Python web frameworks, and the design will be created in Figma and integrated with CSS, both industry standard solutions.
Architecture Design #
- Component Breakdown:

This diagram should showcase all the major internal components.
Web-application communicates with the user, sends the results of their actions to the Database, from which the Judging servers test the solutions, updating the Database, from which the Web-application shows the result to the user.
- Data Management:
We need to store user data, contest data, task data and submission data for our project. Contests need to have several tasks assigned to them, tasks should be able of storing both the task description including images that the creator wants to put in and testing data such as tests or a checker. We will be using the web application to upload to all of these tables, and we will only change entries in the submission data (to update the testing results) and user data (for our users to be able to change passwords). For these purposes, and to easily integrate with Python, we decided to use MongoDB, as it stores data in JSON format and has easy to learn modules for Python.
However, the submissions also need to be put into a work queue, which the judging code (multiple instances of it in fact) needs to pull from. As described in a Kubernetes tutorial, we use a Redis server with several data structures (two queues and a set) to implement the work queue which can re-introduce tasks if they were assigned but not completed in a fixed timeframe and delete tasks if they failed to complete several times.

Integration and APIs: We have no integrations and APIs in our project and will not be using them in the main part of our project. However, we might use APIs in some activities.
Scalability and Performance:
Our project uses Kubernetes, which allows for easy scaling of both the web application and the judging servers. Moreover, all components in a Kubernetes cluster can automatically distribute load between themselves and scale the number of workers as needed.
- Security and Privacy:
Our users’ passwords are hashed, salted and stored in a database. You can only access the database from inside the Kubernetes cluster, so it is not shared around. Nonetheless, while judging, utmost care must be taken as to not let the executed code break the system. Access to the internet is completely disabled and all the code (both the checker code provided by the organizer and the tested code by the contestant) will only be able to see the necessary data (inputs and outputs).
- Error Handling and Resilience:
Kubernetes can perfectly handle errors on its own, restarting and keeping crash logs of all pods (containers). Moreover, at any time more than one instance of the website and judging container are run, so if one crashes, users will be redirected to the other. If a judging container crashes, other containers will use the Redis work queue to detect it and reintroduce the task to be tested (not more than 3 times). Moreover, the Kubernetes distribution we are using ( minikube) comes with a built in dashboard, from where one can easily monitor all activity, see logs and debug the containers. Furthermore, we use persistent volumes to store all the data, so even if the database fails, all data will be safe. All that’s left to do is to log any information in the code itself, which is already partially handled by our website framework, Flask.
- Deployment and DevOps:
Currently, our project uses a bash script to automate local deployment, however, we plan on moving to a proper GitHub Actions CI/CD approach.
This diagram showcases the complete structure of the project: #
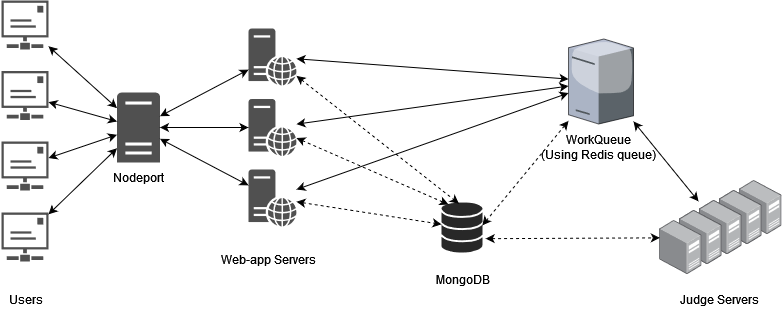
The Users connect to Nodeport, which distributes them to the Web-app server, which updates the database in the MongoDB and asks the WorkQueue to start testing. The WorkQueue distributes the workload on the Judge servers and notifies the Web-app when the testing is complete.
Week 2 questionnaire: #
Tech Stack Resources: We do not plan to use any extra resources other than the ones provided in our System and Network Administration course. We may find some resources during the development, however, most of the relevant information is available and easily searched for on the Web. In the current environment, books are not necessary to learn any of our tech stack.
Mentorship Support: No, we do not have a mentor for our project. No, we never considered having a mentor since our project is rather specific and there are few people that even could help with it, but even then we have one as our team leader. Having a mentor could be useful to create a better vision of the end product and could help with technical or even financial issues.
Exploring Alternative Resources: We have used various sites to help with any immediate questions, including, but not limited to: documentation websites ( Kubernetes, Python, PyMongo, IBM, Redis, Linux and Flask) and forums or blogs where most questions are already answered ( Habr, StackAbuse, BoardInfinity, Aqua Security, Spiceworks, Stack Exchange, SoftwareMill, LiNode and Sentry).
Identifying Knowledge Gaps: We do not know in advance where we have a knowledge gap, but if we encounter one during the development, we will research the topic to the point where we could create an MVP and outline it for future discussion. As a backup, we have a person whose role is to fill in the gaps of our team, so it may become his responsibility.
Engaging with the Tech Community: No, we did not engage with the Tech Community yet. Other than the numerous clubs that are present in the university, we do not have any other means to engage the experts physically. For digital connection one could count the sites we have been using, like StackOverflow, but we could find something in the future, we just do not require anything yet.
Learning Objectives: None. We primarily wanted to share our common knowledge of the existing infrastructure.
Sharing Knowledge with Peers: We have organized knowledge-sharing sessions to bring the team members up to speed with the current state of the project. This was done both offline and online.
Leveraging AI: Our main form of AI usage can be attributed to Google search, since it is now using AI to answer our questions and we ask a lot of them. While some of our team members use LLMs like ChatGPT to quickly get code related to certain features within HTML, we generally do not use LLMs since most of our project is written in Python and all our developers know Python really well and it would take longer to generate and fix code provided by a LLM.
Tech Stack and Team Allocation #
Our project consists of 5 main parts which need to be worked on: the website code, the website appearance, the contest management code. the judging of tasks and system administration.
The website is written using Python with Flask and integrates with the MongoDB database and Redis server. The website uses HTML templates to serve the pages.
The website appearance is mocked up using Figma and implemented using CSS.
The contest management code is fully written in Python and their data is stored using MongoDB.
The tasks are judged using a combination of Python and Bash. Python code is used for organizing and integrating with MongoDB database and Redis work queue, while Bash is used for accurate testing in several programming languages.
Finally, all parts are connected using Kubernetes with separate pods for the website instances, Redis work queue, MongoDB database and judging servers.
| Team Member | Track | Responsibilities |
|---|---|---|
| Fedor Smirnov | Fullstack | Working on system administration, distributing tasks and cleaning up others’ code |
| Ivan Lishchenko | Backend | Public relations, development of code responsible for testing tasks |
| Aleksei Morozov | Frontend | Creating a functional skeleton of the website and integrating it with the database |
| Timur Suleimanov | Backend | Cleaning up the backend and developing features |
| Ivan Sannikov | Design | Mocking up the design of the site and implementing it in CSS |
Weekly Progress Report #
This week the team mainly focused on organizing the workflow among the members by agreement on the future goals the project will fulfill. However, a small part of the technical work has been accomplished:
Some new pages were added to the website, including dedicated pages for uploading tasks and creating contests, and a leaderboard for the contest. A teammate did not fully know how to structure HTML files, so he asked ChatGPT for help.
The tasks were fixed so that they are not stored in persistent volumes in folders, and are instead stored in the database. This was done by a new member of the team, so he had to be “toured” through the code to understand it.
Network isolation was implemented in the judging containers, so that the uploaded code cannot change the database under any circumstances. Furthermore, the means to initialize the database were added as a separate Kubernetes Job with configurable JSON files.
Multiple mockups of the website were produced, including the home page, the login and signup pages, the contest list page and more.
Challenges & Solutions #
We have found out that for reports we need a lot of miscellaneous information from all of our team members, which we did not collect during the week. We have fixed this issue by simply asking again, but as it was on short notice, we were not able to obtain much information, and moving forward we are going to collect more information regarding our actions during the week.
Conclusions & Next Steps #
One of the key conclusions we have from this week is that it is hard to add new members to an existing project, since they need to understand the underlying structure. On any future projects we will try to segregate the work and the structure so that different members do not have to know the other’s work, or barely understand it.
Since this week was mostly spent bringing people up to date with the project, we have a clear goal in sight: we are going to tweak the database management, add a super admin role for better administration, split the web pages to improve user experience and more improvement on the backend.