Week #2 #
Week 2 - Choosing the Tech Stack, Designing the Architecture #
Tech Stack Selection #
For the development of this project, We chose Django and Vue.js primarily for their familiarity and convenience, which enables rapid and efficient development. Django, with its robust framework and built-in features, provides a secure and scalable backend solution. Vue.js, known for its flexibility and ease of integration, offers a reactive and efficient frontend experience. As the project progresses, we plan to integrate PostgreSQL for its powerful database capabilities and reliability. Additionally, we will use Docker for deployment to ensure a consistent and reproducible environment, making it easier to manage and scale the application.
For the AI part we are working with pytorch. Some libs that were useful for us are gTTS, SpeechRecognition, numpy, matplotlib.
Architecture Design #
Component Breakdown:
The project architecture comprises two distinct components:
- Django backend serving as the core API and a Vue.js frontend responsible for user interaction. The backend API handles authentication, data storage, and business logic, ensuring secure and efficient data processing.
- The frontend communicates exclusively with the backend API, utilizing Axios for seamless data retrieval and submission. This separation ensures that sensitive backend operations remain inaccessible to the client-side, enhancing security and adhering to best practices. Through this architecture, the frontend delivers a responsive and intuitive user experience, driven by asynchronous interactions with the backend APIs.
Data Management:
Django’s ORM facilitates seamless interaction with the PostgreSQL database, offering robust data modeling capabilities and ensuring data integrity through schema enforcement and validation. Data access and manipulation are controlled through Django’s powerful querysets and model methods, optimizing database performance. The application employs RESTful APIs to enable communication between frontend Vue.js components and backend Django services, enforcing structured data transmission and ensuring consistency in data representation. Data security measures, including authentication, authorization, and encryption techniques, safeguard sensitive information throughout its lifecycle.
User Interface (UI) Design:
We have opted for a basic design approach during the initial phases of development to prioritize functionality. Our current focus is on implementing core features and ensuring the smooth operation of the website. Once these foundational elements are in place, we plan to seek professional assistance to enhance the user experience and design aesthetics. This approach allows us to efficiently build and test essential functionalities before refining the overall design to deliver an optimal user experience.
Integration and APIs:
Our project integrates essential APIs for speech-to-text and text-to-speech functionalities, which are fundamental to our application’s interactive features. Leveraging these APIs enables our platform to seamlessly convert spoken language into text and vice versa, enhancing accessibility and user engagement. These integrations not only facilitate real-time communication through audio recordings but also empower our users with interactive learning experiences.
Scalability and Performance:
Our architecture is designed to scale efficiently as user demand increases. We will employ scalable database solutions like PostgreSQL and leverage Docker for containerization, ensuring our application can handle growing user bases and increased data processing requirements without compromising performance.
Security and Privacy:
Security is paramount in our application design. We implement best practices such as HTTPS encryption, token-based authentication for API interactions, and secure storage of sensitive user data using technologies like Django’s built-in security features and robust authorization mechanisms.
Error Handling and Resilience:
To maintain reliability, our application includes comprehensive error handling mechanisms. We implement try-catch blocks in critical areas of code, use logging to track errors for debugging, and ensure graceful degradation during unexpected failures to minimize disruption to user experience.
Deployment and DevOps:
For efficient deployment and management, we will utilize Docker containers to package our application and its dependencies. Continuous Integration and Continuous Deployment (CI/CD) pipelines are set up using tools like GitLab CI/CD or Jenkins, enabling automated testing, build, and deployment processes. This ensures rapid and reliable updates to our production environment while maintaining application stability.
Week 2 questionnaire: #
Tech Stack Resources:
Our primary resources are the documentation provided by frameworks like Django and PyTorch and Other libraries we discover through our research.
Mentorship Support:
For now we are working alone without exterior help, except help from our TA Kamil on brainstorming and idea suggestions
Exploring Alternative Resources:
We frequently consult research papers to find new and advanced models that align with our goals. Besides researches, we sometimes turn to popular video tutorials for guidance. We also analyze how established platforms implement similar features and functionalities to ours. By thoroughly studying these resources and research papers, we gain a deep understanding of our tech stack’s features, best practices, and functionalities. This approach helps us effectively apply them in our project to ensure security, scalability, and high performance.
Identifying Knowledge Gaps:
We have identified the points that need further search in the beginning of the week:
- How to detect pronunciation error in the audio
- How to split the audio based on chracters
- What pronunciation metrics are available
Engaging with the Tech Community:
We held a meeting with the development department at the IT park in Kazan and decided to adopt a technology that is well-suited for their future maintenance needs. We also have real-world experience working with our tech stack on projects managed by experts from companies at Kazan, so we can reach out to them for advice when needed. During our discussion, we explored how our project could be applied in educational settings, such as schools and teaching centers, and identified features that could be particularly beneficial for the educational sector.
Learning Objectives:
Audio recognition techniques and metrics
Sharing Knowledge with Peers:
To ensure the effectiveness of our project, we see the importance of knowledge sharing and collaboration within our team. We gathered and analyzed several research papers that provided insights and methodologies relevant to our work. By studying these papers together, we were able to find a method that will make us solve our problem and build the base of our model from it.
Leveraging AI:
We are using the latest technologies in the field of speech recognition to predict the mistakes in the pronunciation of the user. For now, we are primarily working with the wav2vec 2.0 to predict the time ranges for each vocal in the audio file in order for us to be able to show the user where was his problem exactly
Tech Stack and Team Allocation #
| Team Member | Track | Responsibilities |
|---|---|---|
| Yazan Alnakri (Lead) | ML/DS | Searching for relevant articles and implementations |
| Osama Orabi | ML/DS | Searching for relevant articles and implementations |
| Hamza Shafee Aldaghstany | ML/DS | Searching for relevant articles and implementations |
| Amine Trabelsi | Full stack | Build the Website |
| Abdurahmon Abdukhamidov | ML/DS | Searching for relevant articles and implementations |
Weekly Progress Report #
For this week, our team has searched and read more than 8 articles to find the possible approaches we can use. And here are the key research papers that we reviewed and discussed as a team:
- Artificial Intelligence Speech Recognition Model for Correcting Spoken English Teaching
- The Modular Design of an English Pronunciation Level Evaluation System Based on Machine Learning
- wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations.
- Phoneme Segmentation Using Self-Supervised Speech Models
- Application of Word2vec in Phoneme Recognition
- Simple and Effective Zero-Shot Cross-Lingual Phoneme Recognition
- Pronunciation Error Detection and Correction
- The Goodness of Pronunciation Algorithm: A Detailed Performance Study
- An Automatic Pronunciation Error Detection and Correction Mechanism in English Teaching Based on an Improved Random Forest Model
And we read some article about forced alignment to align the output text with the audio: https://research.nvidia.com/labs/conv-ai/blogs/2023/2023-08-forced-alignment/
We have identified the main tasks to work on.
Web:
Substantial progress has been made with a comprehensive rewrite of the codebase. This extensive effort involved refactoring and rewriting utilities and core components to improve code structure, efficiency, and maintainability. Additionally, authentication capabilities were successfully integrated, bolstering the application’s security framework. These advancements not only enhance the overall stability and performance of the platform but also lay a solid foundation for future feature enhancements and optimizations.
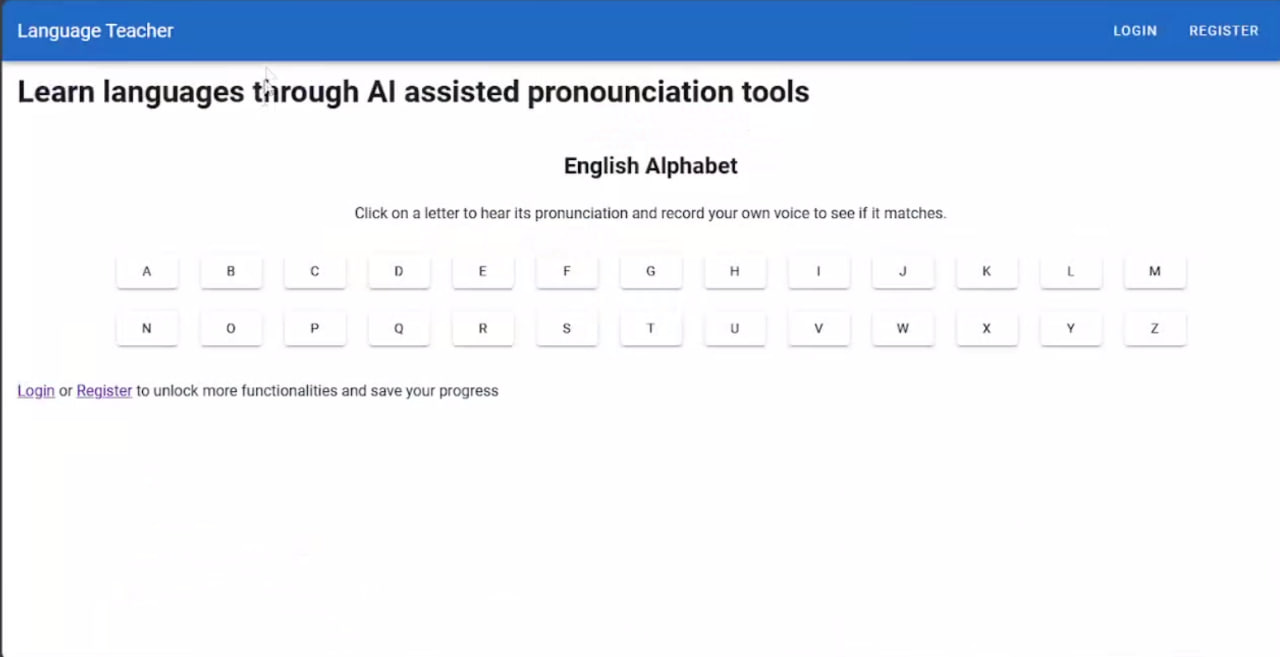
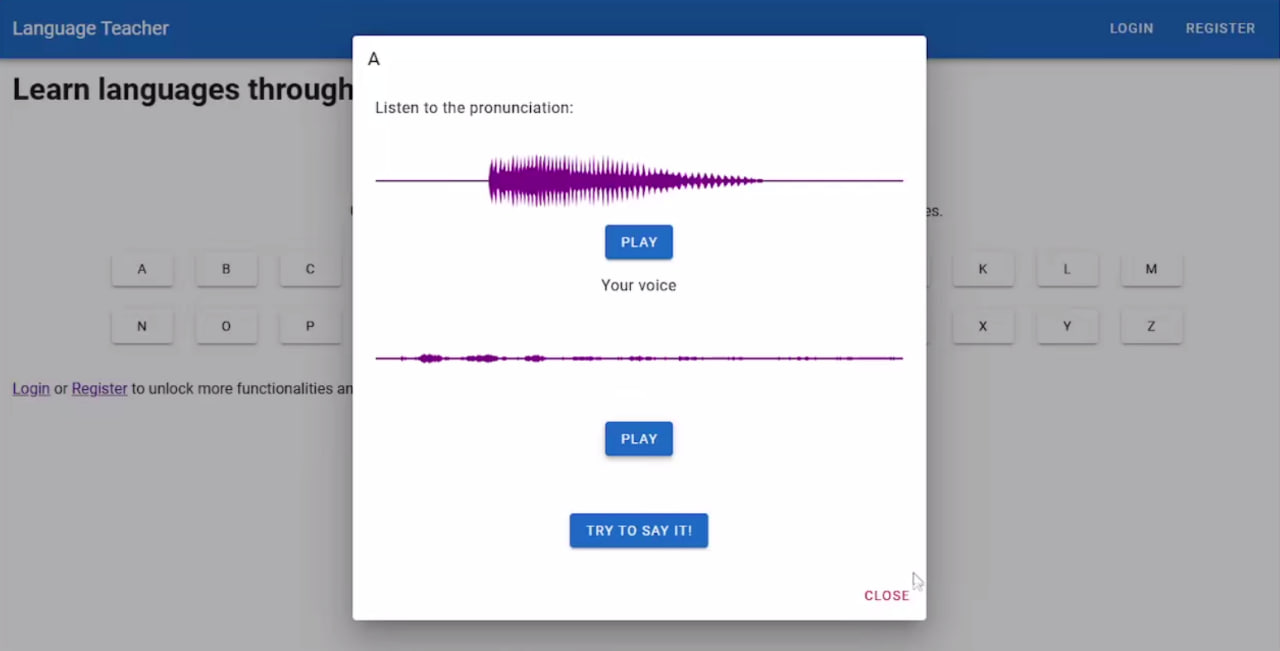
AI:
- text to speech
- speech to text
- denoising audio
- audio to phonemes
- text to phonemes
- adding effects to audio
- found dataset of phonetics
- found wav to phonetics model with good result based on the paper “ Simple and Effective Zero-shot Cross-lingual Phoneme Recognition (Xu et al., 2021 by Qiantong Xu, Alexei Baevski, Michael Auli.”
- For expanding our dictionary of phonetics we will use a model that will predict the output phonetics using IPA phonemes alphabet from the regular language alphabet input.
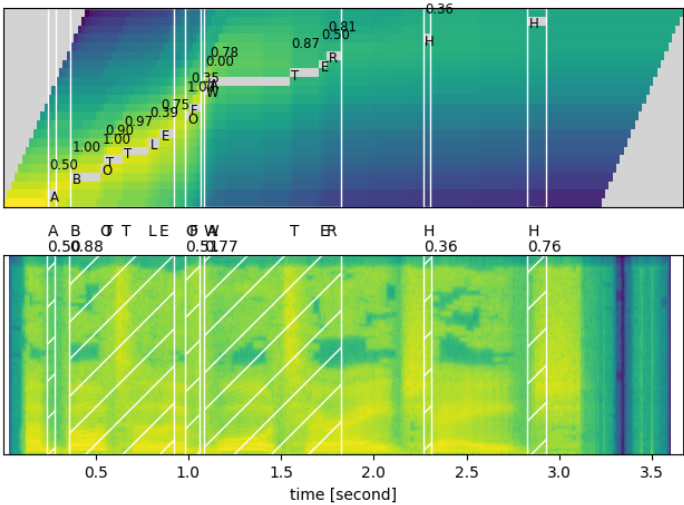
- We applied Forced alignment on the input wav to predict the time boundary of each spoken character(at which moment the predicted character was present in the wav file) as you can see in the image below:
Challenges & Solutions #
File Management and Storage:
- Challenge: Efficiently managing and storing user-uploaded audio files.
- Solution: Utilizing python audio libraries,, storing files in the media directory, and ensuring proper file validation and cleanup.
Frontend-Backend Communication and Security:
- Challenge: Ensuring secure and efficient communication between the frontend (Vue.js) and backend (Django) applications.
- Solution: Implementing CSRF protection in Django, securing API endpoints with authentication and authorization mechanisms (JWT tokens), and using Axios for secure HTTP requests from Vue.js.
Audio to phonemes:
- Challenge: finding a high-accurate method without a big fall-down in metric with little noise in the audio.
- Solution: Found an approach to use the architecture of the wav2vec 2.0 model and train it on outputting phonemes from audio, the approach was proved to be better in case of multiple languages. Also using the denoising model helps in the issue of background noise affecting the evaluation
Phonemes dictionary limitation
- Challenge: Dictionary’s are limited in means of number of words in the language.
- Solution: Found a model that predicts any word’s phonemes with an accuracy of 74% for English.
Conclusions & Next Steps #
To conclude, for now we have extended the plan on how to use machine learning for correcting pronunciation for the user and how to give the user the proper feedback. The reason we chose the phonemes approach is that the results are proven to be generic for languages, even achieving better results when trained on multiple languages compared to the monolinguistic approach(single language).
For next steps, we need to integrate the pronunciation techniques we have implemented to the website. We also need to extend the website to have the user account with some statistics about the progress, main issues, and current level.