Week #2 #
Week 2 - Choosing the Tech Stack, Designing the Architecture #
Tech Stack Selection #
Python 3 🐍
- aiogram3 — for Telegram bot
- pylint — python code linter
- jinja2 — generate emails for email confirmation, generate json file for crashes
HTML/CSS — appearance of email confirmation
React ⚛️ — appearance of WebApp for admin panel
MongoDB 🌱 — a database for storing the state of bot users
CI/CD ⚙️
- GitHub Actions — fully qualified CI/CD pipelines with the immediate pushing of the latest version of product
- bash — for writing automation scripts
- SonarQube — linter for the code quality
Docker 🐳 — running microservices in containers
Docker-compose 🐙 — managing the launch sequence of all containers
Java 21 ☕️
- SpringBoot 3.2 — Web, REST Controllers
- SpringBoot WebFlux — HttpClient
- SpringData JPA — database manipulation
- SpringBoot Metrics (Actuator, DevTools) — metrics
- Lombok — Code Boilerplate Reduction
- JUnit, AssertJ, TestContainers — Unit + Integration Test
PostgreSQL 🐘 — main database with all records about reports
Liquibase — version management of DB (migrations)
Architecture Design #
Component Breakdown:
Backend Components
API:
- Serve as the primary interface for data interaction between the frontend, Telegram bot, and databases.
- Handle requests related to reporting issues, fetching user data, and managing statistics.
- Ensure secure and efficient communication between components.
Interactions:
- Receives and processes data from the Telegram bot and WebApp.
- Communicates with PostgreSQL for report storage.
- Interfaces with the LLM system for comment analysis.
PostgreSQL Database for reports:
- Store and manage reports related to dormitory infrastructure issues.
- Maintain data integrity and support complex queries for report statistics and analysis.
Interactions:
- API communicates with PostgreSQL to store, retrieve, and update report data.
- WebApp queries PostgreSQL for generating statistics and reports.
MongoDB Database for bot:
- Store and manage user information, including user profiles and interaction history.
- Provide a flexible schema for handling diverse user data.
Interactions:
- Telegram Bot uses MongoDB to store, retrieve, and update user information.
LLM System:
- Analyze comments in reports to extract insights and detect patterns.
- Assist in categorizing issues and providing additional context for reported problems.
- Summarize comments in several reports to identify one common problem.
Interactions:
- Receives comments from the API for analysis.
- Sends analysis results back to the API to enhance report data.
Frontend Components
Telegram Bot (+ REST Listener):
- Provide a user-friendly interface for students to report issues.
- Collect data such as the type of failure, location, and user comments.
- Send notifications and updates to users about the status of their reports.
- Perform authorization for security.
Interactions:
- Sends collected report data to the API.
- Receives notifications and updates from the API to send back to users.
WebApp for Admins:
- Provide a dashboard for administrators to view statistics and manage reports.
- Display data visualizations for better understanding of infrastructure issues and user interactions.
- Allow admins to update report statuses and communicate with users if necessary.
Interactions:
- Queries the API to fetch report data, user information, and analysis results.
- Displays statistics and insights fetched from PostgreSQL and MongoDB.
Data Management:
Our system has two databases for reports (PostgreSQL) and for user information (MongoDB).
PostgreSQL Database (for Reports)
Why we deciced to choose this database:
- Relational database structure to handle structured data efficiently.
- Support for advanced querying and indexing to enhance performance.
- ACID compliance to guarantee transactional integrity and reliability.
Purpose:
- Store and manage all reports related to dormitory infrastructure issues.
- Ensure data integrity, support complex queries, and facilitate efficient data retrieval for reporting and analysis.
Data Types Stored:
Report ID, category of failure, placement, failure date, proceeded date, owner email, information about failure confirmation by admin or analysis mechanism, information about resolving problem by admin or user, full description.

MongoDB Database (for User Information)
Why we deciced to choose this database:
- NoSQL database structure for handling unstructured and semi-structured data.
- Schema-less design allowing easy updates and scaling.
- High availability and scalability to accommodate growing data volumes.
Purpose:
- Store and manage user information, including user profiles and interaction history.
- Provide a flexible schema to handle diverse and evolving user data requirements.
Data Types Stored:
User ID, name, contact details, interaction history, including reports submitted and notifications received.
User Interface (UI) Design:
Since our system involves user interaction, its design is crucial. We selected a Telegram bot for user engagement due to its simplicity and ease of use. The accompanying image illustrates the communication logic between the user and the bot, highlighting the intuitive flow we want to implement.
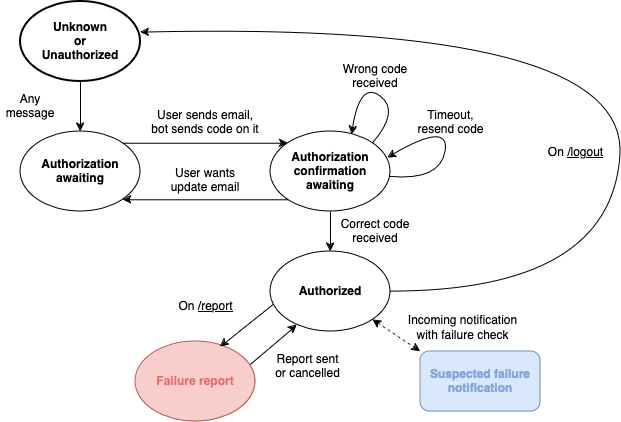
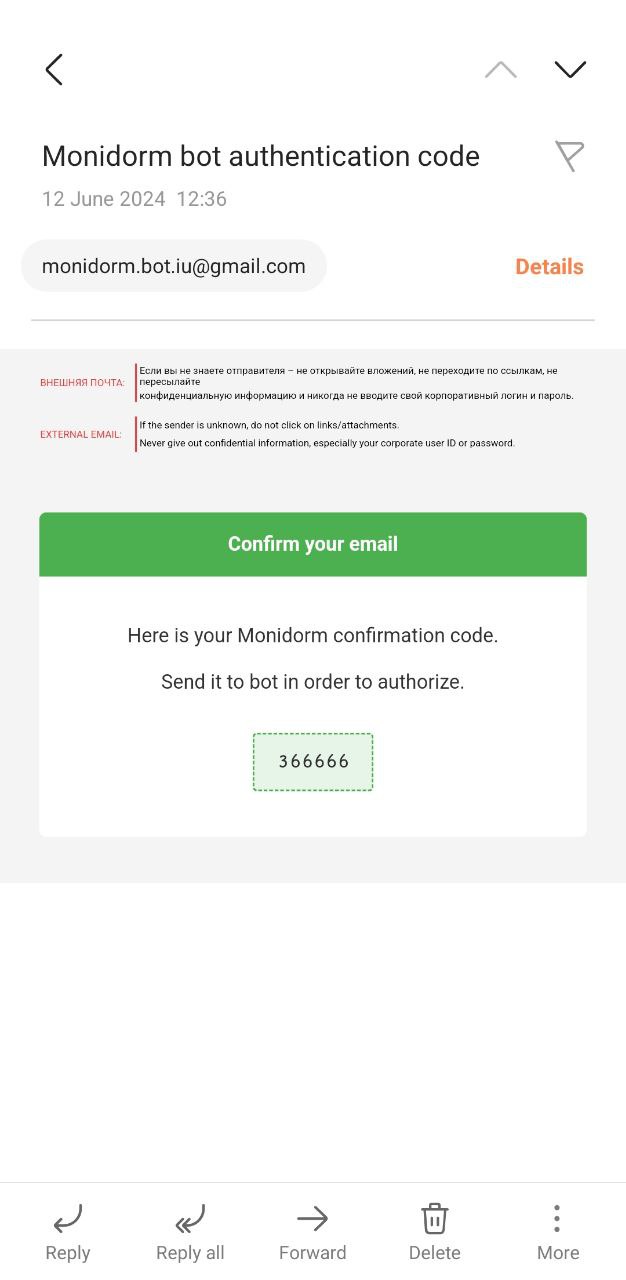
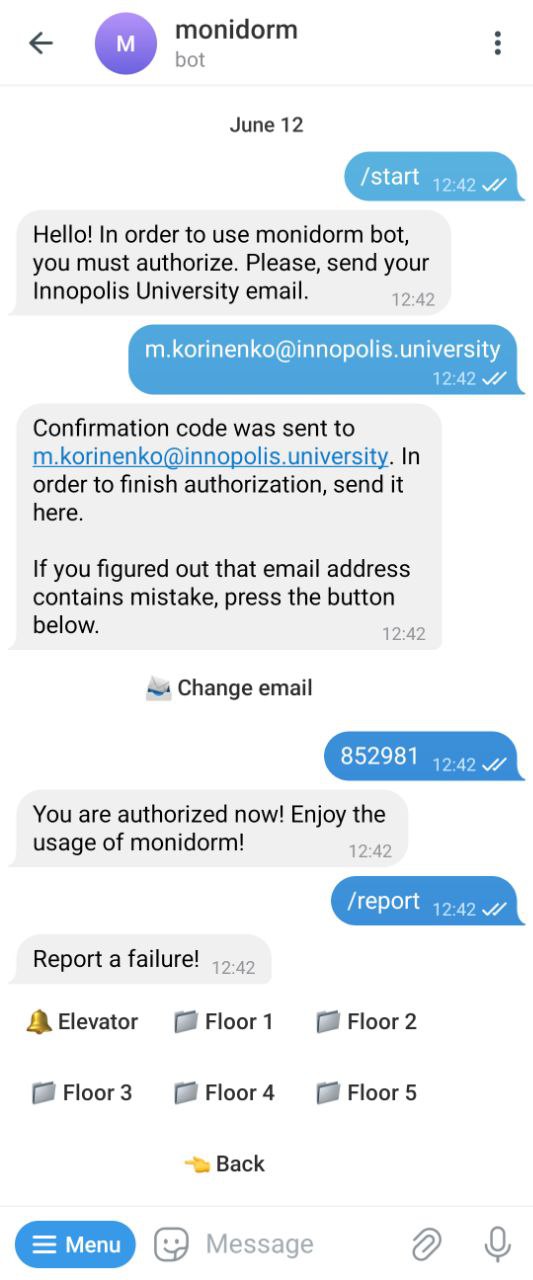
Below is an illustration of user authorization and interaction with the bot.
As one of the components of our project is the WebApp, its design requires careful consideration. Currently, we are in the process of creating its design, focusing on optimizing elements to ensure administrators can easily navigate and swiftly access essential information.
We also designed several logos for our system to ensure that users immediately grasp its purpose. In the future we will select one of these logos.

Integration and APIs:
We plan to use integration for LLM service. For now, we want to run a python microservice using an integration with OpenAI API to summarise text. This API will communicate with a Java server and handle comments. Another possible scenario is to use an open-sourced self-hosted LLM service on a Java server.
Scalability and Performance:
In the future, we plan to expand the use of our system and implement it for larger universities, districts, and even cities. To accommodate future application growth and increased user load without sacrificing performance, we incorporated several aspects of scalability into the MoniDorm architecture:
- Microservices Architecture: We use a microservices architecture to separate different functionalities of the application (API, Telegram bot, LLM system, WebApp) into independent services. This modular approach allows each service to scale independently based on demand.
- Database Scalability: We use PostgreSQL for storing reports due to its robustness and ability to handle large datasets. Moreover, MongoDB for storing user information is chosen for its flexible schema design and horizontal scaling capabilities. We will use the built-in striping feature to distribute data across multiple servers, which will ensure that large amounts of user information can be processed efficiently.
- Docker and Docker-compose: By containerizing our microservices with Docker and managing them with Docker-compose, we can easily deploy, scale, and manage multiple instances of each service.
- CI/CD Pipeline in GitHub: We will use CI/CD pipeline to provide continuous integration and deployment, allowing us to quickly release updates and scale the application without downtime. Automated testing and deployment also helps maintain stability and performance.
- Spring Boot Metrics: Using Spring Boot Actuator and other monitoring tools, we will continuously monitor application performance and resource utilization. This data will help us proactively address any scalability issues and optimize performance in the future.
By incorporating these scalability considerations into our architectural design, MoniDorm will be well prepared for increased user load and data volumes, ensuring consistent performance and reliability as the application grows.
Security and Privacy:
To protect user data and guard against potential vulnerabilities, we have integrated a set of security measures into the MoniDorm architecture.
When a user interacts with the MoniDorm Telegram bot for the first time, they are prompted to authenticate by entering a one-time code sent to their registered email to confirm their identity. Users are assigned roles based on their status, such as regular user or administrator. The bot verifies these roles before granting access to specific commands and functions; for instance, only users with the ‘admin’ role can access administrative commands.
To ensure secure system operation, the admin role is added manually in the database, preventing unauthorized individuals from accessing sensitive data from reports. Additionally, we plan to use SonarQube to check our code for security and maintainability issues, monitor code coverage, detect code smells, and enforce manual security checks if needed. Given our extensive database integrations, ensuring their security is a top priority.
Also, all API keys and passwords will not be stored in the code directly. This will be done via GitHub secrets and they will be inserted during the pipeline.
Error Handling and Resilience:
Most part of our application is covered by Unit and Integration Tests. This provides reliability when developing new functionality that the application will not break. In addition to checking that the application was successfully built, tests are run to check for RunTimeErrors. The frontend is tested manually by team members and all interface bugs are accounted for.
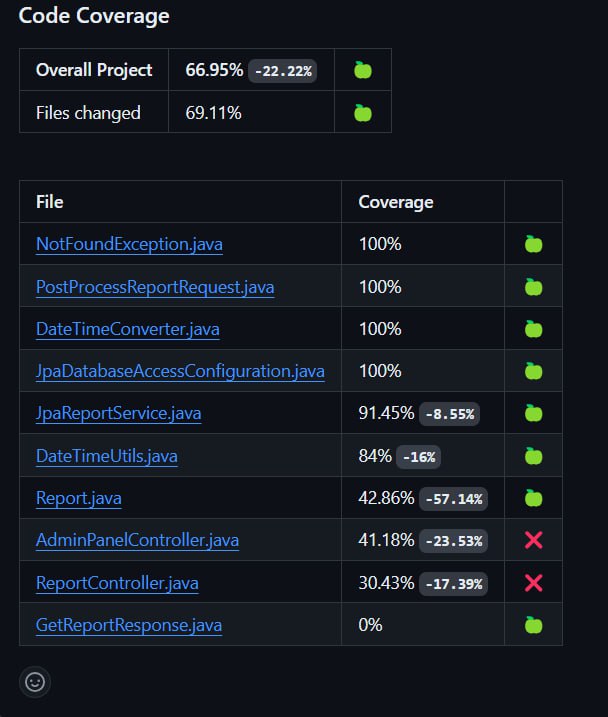
Deployment and DevOps:
We follow DevOps principles and use tools for secure and rapid deployment. Since our application is a microservice architecture, all services reside in Docker containers that are run on servers using Docker-compose. Before being deployed to the servers, the code goes through a CI/CD pipeline where it is built and tested.
We ensure the robustness and security of our deployment process by integrating various stages in our CI/CD pipeline, including:
- Automated Testing: All code changes undergo rigorous automated tests to ensure functionality and stability. This includes unit tests, integration tests, and end-to-end tests.
- Static Code Analysis: Tools like SonarQube are used to analyze the code for potential bugs, code smells, and vulnerabilities.
- Continuous Integration: Every code change triggers a build process, ensuring that all parts of the application are compatible and work as expected when integrated.
- Continuous Deployment: Once the code passes all the tests and checks, it is automatically deployed to our staging environment for further testing. If everything is verified, it moves to production.
Looking ahead, we plan to enhance our deployment strategy by integrating Kubernetes and Terraform:
- Kubernetes: By leveraging Kubernetes, we aim to improve the scalability and management of our containerized applications. Kubernetes will help us orchestrate our Docker containers, manage their lifecycle, and scale them based on demand.
- Terraform: To manage our infrastructure as code, we plan to use Terraform. This will allow us to define our infrastructure in configuration files, making it easier to provision and manage. Terraform will enable us to create, update, and version our infrastructure safely and efficiently.
By incorporating Kubernetes and Terraform, we will further enhance our ability to deploy and manage our microservices in a scalable, reliable, and secure manner. This will also streamline our infrastructure management, reduce manual interventions, and ensure that our deployment process remains consistent and reproducible across different environments.
Week 2 questionnaire: #
Tech Stack Resources:
At present, we do not utilize any project-based books. Instead, we rely extensively on the documentation and resources provided by the frameworks that we are employing.
Mentorship Support:
Currently, we do not have a mentor involved in our project, as our idea is in the early stages of development. However, we are considering the option of hiring a mentor in the future to enhance our system and expand its scope beyond the student dormitory level. After implementing the minimum functionality of our project, we plan to seek feedback from the dormitory administration. This feedback will be invaluable, as it will allow us to effectively tailor the project to our target audience and facilitate its adoption by users.
Exploring Alternative Resources:
We have explored various other resources to expand our understanding of the technology stack. These include online courses, video tutorials, and comprehensive documentation.
The documentation acted as the definitive reference for syntax, features, and best practices, ensuring standards compliance, optimization of our implementations, and code cleanliness:
The tutorials provided practical knowledge and examples to facilitate the implementation and debugging of our technology stack components:
By utilizing these diverse resources, we were able to deepen our understanding of our technology stack, overcome challenges, and ensure the robust development of MoniDorm.
Identifying Knowledge Gaps:
We have not worked with LLM before, but we have an idea of how to work with API. Maybe there are nuances there that we don’t know about yet.
We have no experience in creating a WebApp on React, since the frontend was originally supposed to be on Svelte. We also have difficulties with working with Grafana
Fortunately, for all technologies we found the necessary documentation and started to study it.
Engaging with the Tech Community:
We frequently turn to online forums and groups, such as Stack Overflow, to ask and review questions related to Python, Docker, Spring Boot, and other components of our technology stack. Additionally, we use GitHub repositories to explore open-source projects, where we can find answers to our questions and extract practical information from code reviews and community feedback.
Learning Objectives:
The main learning objectives of this week was to learn how to send email confirmations, connect the interface to the database, and set up configuration files on a remote server. We successfully achieved these goals by reading documentation, using internet resources and writing code in sandboxes. This helped us to learn and practice new skills.
Sharing Knowledge with Peers:
As a team, we have established an effective information-sharing strategy. We use a Telegram chat divided into several sections (general, project reports, meeting organization, useful resources, daily reports). This structure facilitates easy access to necessary information, ensuring each team member quickly inform about project updates. Our communication extends beyond the digital space because we organize two meetings every week (one at the beginning and one near the end), where all team members participate. These meetings that are conducted either offline or online allow us to discuss achieved results and plan next steps. Additionally, team members working on the same component can arrange extra calls or meetings during the week as needed.
We organize week-long sprints to enhance productivity, using GitHub issues to track tasks, assign responsibilities, and label components. To avoid last-minute rushes, we report daily on our progress to motivate each other and keep everyone informed about the project’s status.
Leveraging AI:
We sometimes use artificial intelligence-based tools, in particular ChatGPT, to accelerate knowledge acquisition and improve the development process. ChatGPT provides instant resolution of technical issues, helps us understand complex concepts, and supplements formal documentation with explanations. We also use AI-based code review tools to optimize performance and maintain high code quality. This AI integration has accelerated our learning, increased productivity, and enhanced the overall capabilities of our team, allowing us to solve problems more efficiently and stay up-to-date on the latest best practices.
Tech Stack and Team Allocation #
| Team Member | Track | Responsibilities |
|---|---|---|
| Evgeny Bobkunov | Project Management | Team management, GitHub repository support, Issues creation and task tracking |
| Matvey Korinenko | Team Lead, Fullstack | Creating a Telegram bot as a frontend interface for users, Development of the project architecture, Working with MongoDB database |
| Artur Mukhutdinov | Backend, Deputy Team Lead | Development of API and architecture, Working with PostgreSQL database |
| Daniil Prostiruk | Frontend | Development of Telegram WebApp for the administration panel |
| Rufina Gafiiatullina | ML, DS | Exploring the feasibility of applying LLM to the project, Development of a fault detection algorithm |
Weekly Progress Report #
Team Work: #
We conducted 2 offline and 2 online meetings, where we discussed architecture of microservices, API, database structure and LLM. Results of these meetings are stored in wiki.
Telegram Bot: #
The bot’s interface is implemented
Authentication by mail has been added
Added persistence for bot, using MongoDB
API Server: #
Filter for security token
Integration with PostgreSQL database via Spring Data JPA
Swagger specification via openapi-doc
Implementation of REST API service
Automatic migrations of database schemas at service startup
Integration testing, using testcontainers
Challenges & Solutions #
We also faced challenges this week:
Frontend Admin panel:
- Grafana did not display graphs and charts on Svelte site. We solved this problem by moving to another web framework: React. It was more suitable not only for working with Grafana, but also for working with Telegram WebApp.
API Server:
- We had difficulties in writing the contract. We had constant revisions going on. And we were reworking the existing version. We were able to solve this problem by updating our approaches to the vision of the contract.
Deployment:
We encountered difficulties in deploying services to a remote machine, had problems in configuration setup.
We had difficulty setting up CI/CD as there was no way to add a self-hosted runner in GitHub.
Conclusions & Next Steps #
We have done a lot of work and written the basic code for the API server and the Bot, Next we are going to connect them so that communication via contracts happen. Also, we are starting to research LLM for our project and slowly developing an adimn panel in the form of a WebApp.