Week #3 #
Developing the prototype, creating the priority list #
Technical Infrastructure: #
Development Environment (issues) #
Currently, everyone is working online by sharing data on GitHub and analyzing everything. For instance, backenders and frontenders namely Anushervon, Muhammad, and Ivan are working on their machines and developing their parts. Due to technical issues, some of the backend’s tasks are tested on Illia’s laptop, since only his device can run LLM models. We are thinking of hosting his part so that other colleagues can continue developing their project tasks.
We have researched some ways to host our application: using CPU only or GPU servers.
- CPU server for test purposes
- GPU for demo day if the CPU server lacks performance
We have not created a Development Environment yet, since the need to use LLM models outside the ML engineer arose during integration on the weekends, so the first priority for the following week is to get a server since it is needed for testing purposes too
Overall #
We organize study-coding sessions every two days, where our team:
- Develop our product
- Share opinions
- Discuss plan of action for the next few days
Backend Development: #
This week, we were developing API endpoints using Django Rest Framework.
Authentication Endpoints
SignUp - POST endpoint
- Parameters:
username,email,first_name,last_name,telegram_id - Description: When the parameters are provided the request is validated by UserSerializer. If it is valid, create a new user account and return a success response with the user data and a 201 status code. If data is not valid, it returns an error response with the validation errors and a 400 status code.
- Parameters:
SignIn - POST endpoint
- Parameters:
username,password - Description: After providing parameters it validates the request data using the SignInSerializer and, if valid, authenticates the user with the provided username and password. If the authentication is successful and the user is active, it returns a token in the response with a 200 status code. If the user is not active or the credentials are invalid, it returns an error message with a 400 status code. If the data is invalid, it returns the validation errors with a 400 status code.
- Parameters:
SignOut - POST endpoint
- Description: Deletes the user’s authentication token, effectively ending their session. Only authenticated users can access this endpoint.
ML Model Integration Endpoints
SummaryView - POST endpoint
- Parameters:
query(string) - Description: Returns a summary of the query.
- Parameters:
QuizView - POST endpoint
- Parameters:
text(string) - Description: Returns a quiz based on the text. The
textparameter is validated using theTextSerializer. If the text is valid, it’s used to generate a quiz, which is then returned in the response. To use this endpoint, make a POST request with a JSON body containing thetextparameter.
- Parameters:
These endpoints provide a robust interface for user authentication and interaction with ML models.
ML #
Quiz Generation #
Quiz Generator now uses Pydantic output parser:
- Validates if output corresponds to request in a prompt
- Automatically converts the model output to the data type (Pydantic model), so it can be easily passed to the Backend without any extra steps
Router for Backend integration #
The router stands as gateway/abstraction layer between the Backend ob Django and the LLM Model on LangChain (LangGraph usage was omitted since currently, we do not need flexibility). Our backend API uses a router, so any changes in the ML logic will not affect the backend API as long as router function signatures does not change
Frontend Development: #
Behind-the-scenes part #
- Implemented receiving authentication from POST endpoints from backend (described above). Svelte stores allow for caching user’s authentication and data, so we used svelte stores to handle incoming data.
UX/UI #
- We decided to make the design of our app to be as usable as possible. For that we drew inspiration from Google’s service, Google Drive. Main inspiration were the top and left bar: while being rather simplistic, they provide vast functionality. Here is an example screenshot:
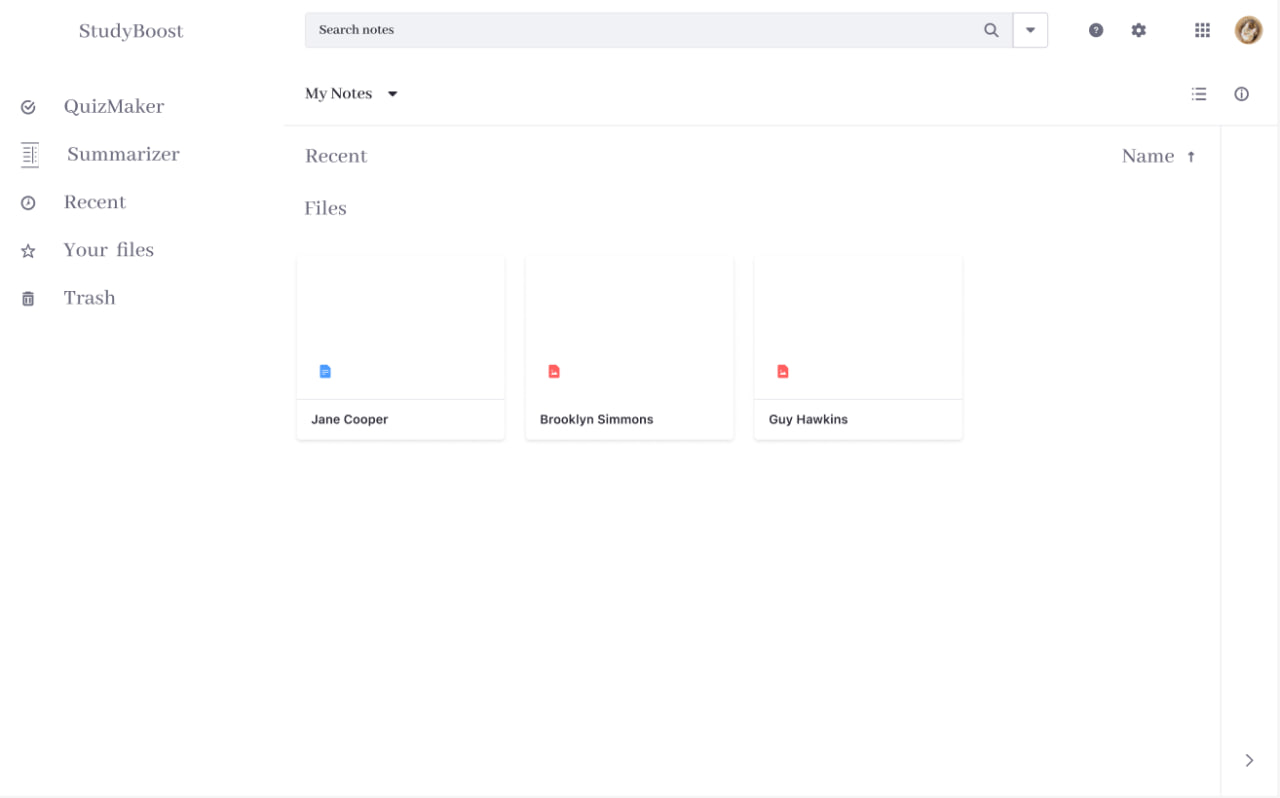
- Worth noting, that further work on UI will be needed since for now, not all of the features have been implemented.
Data Management: #
Relational Database #
By utilizing PostgreSQL we aim to store user info to be able to sign him so that he can use the application
Vector Database #
Vector Database works with the backend and could be used in model pipeline, but before adding this feature some functionality robustness must be addressed.
Prototype Testing: #
Vector Database #
Security of newly added files will be a crucial consideration in the near future, as there is a risk that users may upload malicious content. However, for now, we need to prioritize tasks that address core functionality and improve overall performance. Possible solution is to allow people with some rights to use this feature or to use another LLM / semantic router for discovering malicious content.
For now it is possible to add many identical documents - future vector retrieval could get these document at once, so the main idea of using vector database with retrieval shutters.
Summary generator #
No problems were detected, but we need to handle larger text sizes since the model context size is limited
Quiz Generator #
Quizzes structure is validating during generation by using the Pydantic output parser for LLM in the LangChain - All field types are consistent, so further action does not need any validation - Model generation has high dependency on input data from text spliters, here are some examples of how it influences the question (Quiz was generated using this Wikipedia page and we obtained 124 questions - here full list of questions we get):
```
# Questions with problems - need to add more validation checks
# Bad data split - bad results
Question(
question="What is the text?",
options=["Earth", "Mars", "Jupiter", "World"],
correct_answers=["World"],
)
# Actually correct answers, but no accordance to provided options
Question(
question="What is the Second Ideal for the Order of Windrunners?",
options=[
"I will protect even those I hate, so long as it is right",
"I accept that there will be those I cannot protect",
"Manipulate the Surges of Adhesion and Gravitation",
"Bonded to Honorspren",
],
correct_answers=["I will protect those who cannot protect themselves"],
)
Question(
question="What is the Surge manipulation ability for Truthwatchers?",
options=[
"Manipulate the Surges of Adhesion",
"Manipulate the Surges of Gravitation",
"Manipulate the Surges of Division",
"Bonded to Mistspren",
],
correct_answers=["Manipulate the Surges of Progression and Illumination"],
)
# Some-why model decided to change answering strategy
Question(
question="How many branches are there in Surge binding?",
options=["Five", "Ten", "Twenty", "Thirty"],
correct_answers=["B"],
)
# Quite good questions
Question(
question="What are Spren according to the second book?",
options=[
"Physical forms of humans",
"Concepts and ideas are given physical form by the human collective subconscious",
"Intelligent beings from another realm",
"Creatures that can only be seen in Shadesmar",
],
correct_answers=[
"Concepts and ideas are given physical form by the human collective subconscious"
],
)
Question(
question="What is unique about the Siah Aimians?",
options=[
"They have dark skin and hair",
"They can change their bodies slightly",
"They have white-blue skin and shadows that point the wrong way",
"They are made of many small creatures with exoskeletons",
],
correct_answers=[
"They have white-blue skin and shadows that point the wrong way"
],
)
```
Weekly Progress Report: #
This is the result of our team’s work.
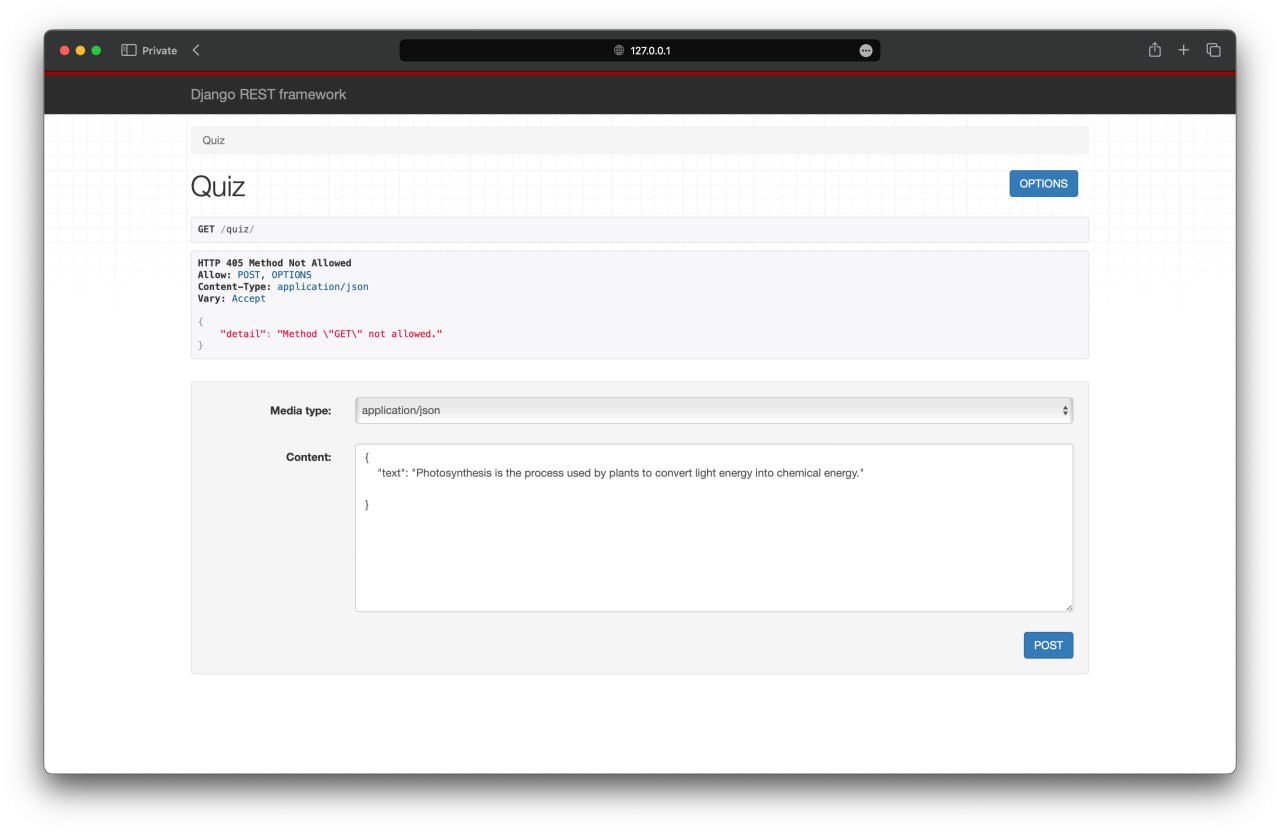
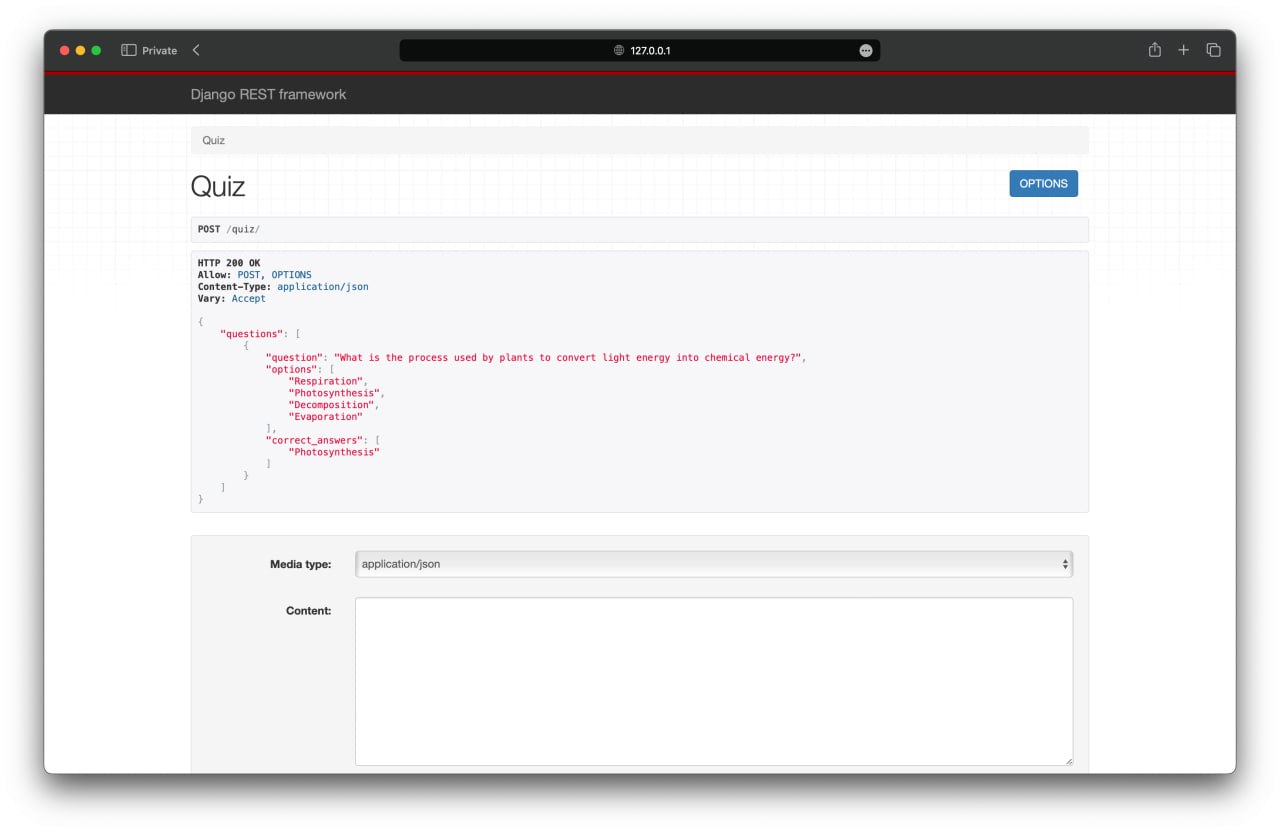
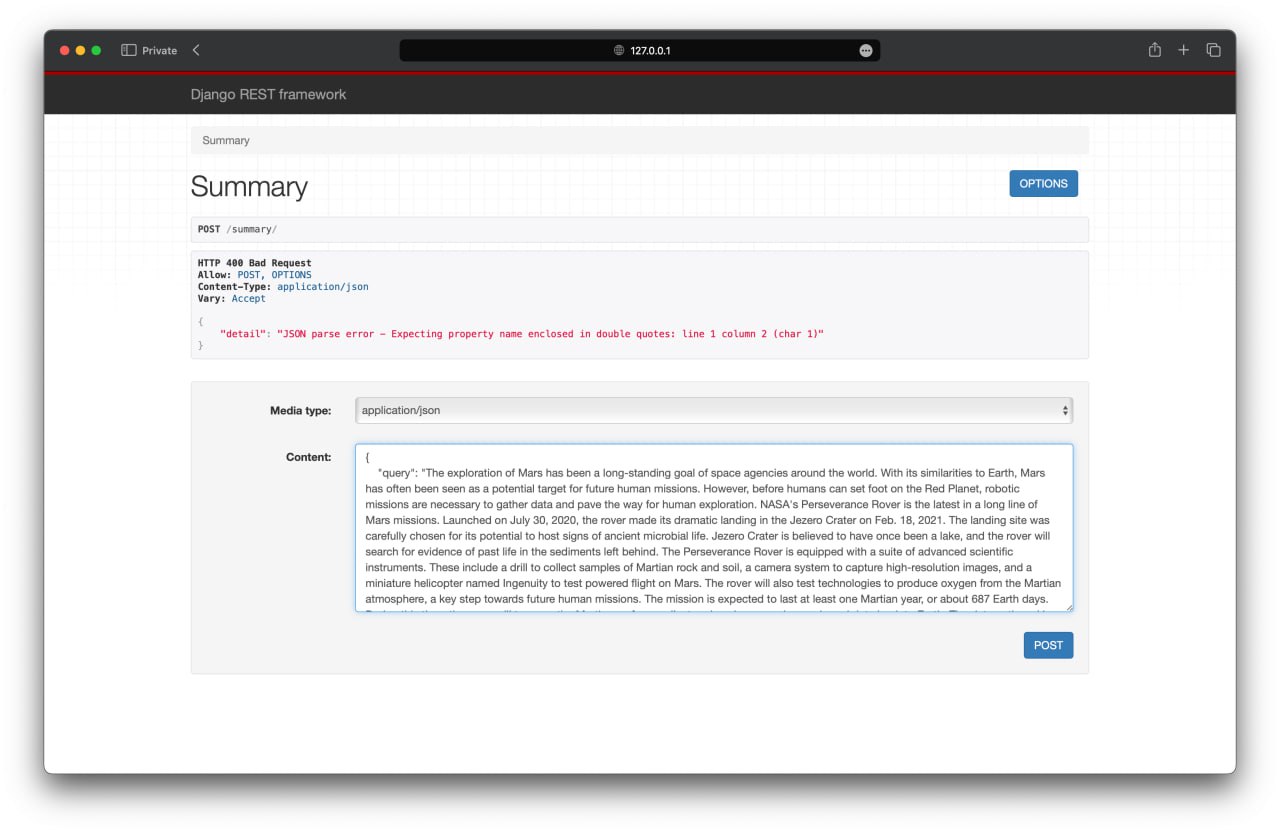
Challenges & Solutions #
Model Behavior #
It was hard to make the model use pedantic validation: the challenge with model failing to follow instructions and putting some useless replicas or data with failing every validation.
- The first step was prompt optimization, some class structure reorganization. After these steps, the model started to pass validation (at least each 5th try was a success).
- The second step was to understand, that the Pydantic model was slightly incorrect, so Quiz and Question models were made: The Quiz consists of a list of Questions. This step made the model give quite good JSON-like output, but some phrases were still appearing, such as “Here is your quiz”, etc.
- The third step was to discover, that the model used for generation is the Llama3:8b Chat model and by using Llama3:instruct no problems arose. The conclusion is to research the tasks for which the model was created.
Team coordination #
Do not permit workarounds or quick fixes that involve commenting out problematic code. Instead, require proper error resolution when issues arise during integration, as temporarily addressing errors through ‘comment-out fixes’ can create unintended bugs, particularly if these ‘fixes’ are committed to the main repository (e.g., GitHub).
Conclusions & Next Steps #
Conclusions #
This week was crucial for our team especially, for the prototype development. We were focused on setting up basic features like working with models, namely quiz generation and model output behavior understanding and parsing. We are planning to facilitate the working process of these functions, also more focus on the frontend side that would be beneficial for us.
Next Steps #
- Design and build an asynchronous way to use Quiz Generation, since users most of the time do not need all questions at once, so we could deliver questions one by one as they generate. For this, we need to change the Django Backend structure and ML model calling design
- By doing this, we could lower the initial waiting time for users to get the first question
- Time for generating all quizzes stays the same, but it is distributed among users more-or-less evenly
- The code logic complexity increases, so the better way is to plan these features ahead
- Continue the work on frontend
- Implement other POST requests reception and sending.
- Continue the never-ending work on improving the UI and UX.
- Finalize all the necessary windows, pages and pop-ups.